
DeepStream-test1-python-demo样例
DeepStream-test1-python-demo样例
基于知乎博客解释完成:
https://zhuanlan.zhihu.com/p/359079725
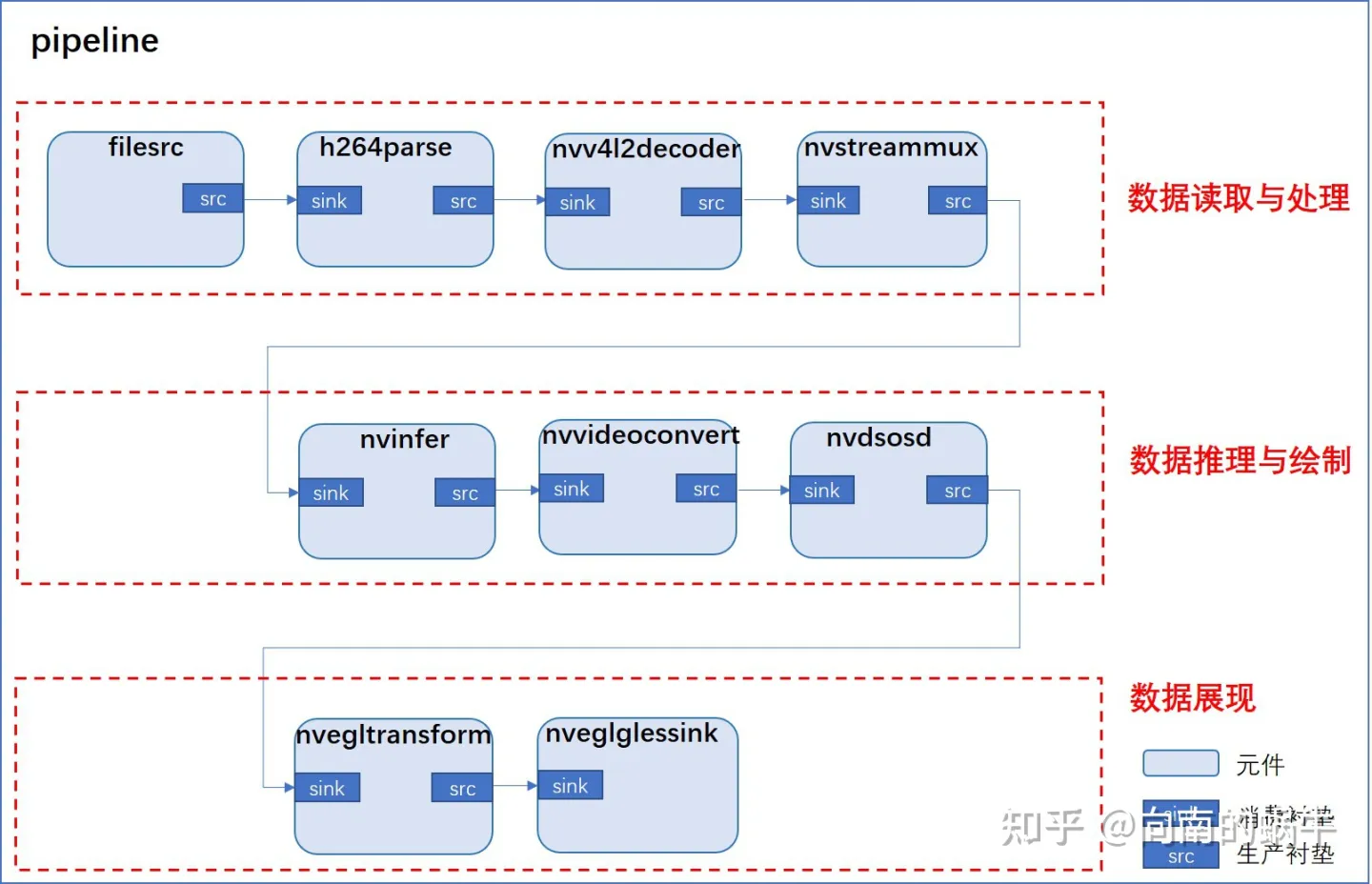
大致整体流程:
test1样例的整体流程: 首先数据源元件(filesrc)负责从磁盘上读取视频数据,解析器元件(h264parse)负责对数据进行解析,编码器元件(nvv4l2decoder)负责对数据进行解码,流多路复用器元件(nvstreammux)负责批处理帧以实现最佳推理性能,推理元件(nvinfer)负责实现加速推理,转换器元件(nvvideoconvert)负责将数据格式转换为输出显示支持的格式,可视化元件(nvdsosd)负责将边框与文本等信息绘制到图像中,渲染元件和接收器元件(nvegltransform and nveglglessink)负责输出到屏幕上.
代码详解
main函数
在主函数中调用gst_init()来完成相应的初始化工作,以便将用户从命令行输入的参数传递给GStreamer函数库
Gst.init(None)
创建主循环,在执行 g_main_loop_run后正式开始循环
loop = GLib.MainLoop()
在GStreamer框架中管道是用来容纳和管理元件的,下面将创建一条名为pipeline的管道:
pipeline = Gst.Pipeline()
创建管理中需要使用的所有元件,并检查所有元件是否创建成功
print("Creating Source \n ")
# 创建一个gstreamer element, 类型为filesrc,名称为file-source。
source = Gst.ElementFactory.make("filesrc", "file-source")
if not source:sys.stderr.write(" Unable to create Source \n")# Since the data format in the input file is elementary h264 stream,
# we need a h264parser
print("Creating H264Parser \n")
# 创建一个gstreamer element, 类型为h264parse,名称为h264-parser。
# 因为输入文件中的数据格式是基本的h264流,所以我们需要一个h264解析器
h264parser = Gst.ElementFactory.make("h264parse", "h264-parser")
if not h264parser:sys.stderr.write(" Unable to create h264 parser \n")# Use nvdec_h264 for hardware accelerated decode on GPU
print("Creating Decoder \n")
# 创建一个gstreamer element, 类型为nvv4l2decoder,名称为nvv4l2-decoder。
# 调用GPU硬件加速来解码h264文件
decoder = Gst.ElementFactory.make("nvv4l2decoder", "nvv4l2-decoder")
if not decoder:sys.stderr.write(" Unable to create Nvv4l2 Decoder \n")# Create nvstreammux instance to form batches from one or more sources.
# 创建一个gstreamer element, 类型为nvstreammux,名称为stream-muxer。
# 从一个或多个源中来组成batches
streammux = Gst.ElementFactory.make("nvstreammux", "Stream-muxer")
if not streammux:sys.stderr.write(" Unable to create NvStreamMux \n")# Use nvinfer to run inferencing on decoder's output,
# behaviour of inferencing is set through config file
# 创建一个gstreamer element, 类型为nvinfer,名称为primary-inference。
# 使用nvinfer在解码器的输出上运行推理,推理过程的参数是通过配置文件设置的
pgie = Gst.ElementFactory.make("nvinfer", "primary-inference")
if not pgie:sys.stderr.write(" Unable to create pgie \n")# Use convertor to convert from NV12 to RGBA as required by nvosd
# 创建一个gstreamer element, 类型为nvvideoconvert,名称为converter。
# 使用转换器插件,从NV12 转换到 nvosd 所需要的RGBA
nvvidconv = Gst.ElementFactory.make("nvvideoconvert", "convertor")
if not nvvidconv:sys.stderr.write(" Unable to create nvvidconv \n")# Create OSD to draw on the converted RGBA buffer
# 创建一个gstreamer element, 类型为nvdsosd,名称为onscreendisplay。
# 创建OSD在转换后的RGBA缓冲区上绘图
nvosd = Gst.ElementFactory.make("nvdsosd", "onscreendisplay")if not nvosd:sys.stderr.write(" Unable to create nvosd \n")# Finally render the osd output
# 判断平台类型,是否需要转化 nvegltransform?
# 判断设备平台是否为TEGRA,是的话创建transform元件,实现渲染osd输出。
# 这个属性是在makefile文件中设置的。
if is_aarch64():print("Creating nv3dsink \n")sink = Gst.ElementFactory.make("nv3dsink", "nv3d-sink")if not sink:sys.stderr.write(" Unable to create nv3dsink \n")
else:print("Creating EGLSink \n")sink = Gst.ElementFactory.make("nveglglessink", "nvvideo-renderer")if not sink:sys.stderr.write(" Unable to create egl sink \n")print("Playing file %s " % args[1])
# 数据源元件负责从磁盘文件中读取视频数据,它具有名为location的属性,
# 用来指明文件在磁盘上的位置。使用标准的GObject属性机制可以为元件设置相应的属性
# 这里是为source元件的location属性赋值,
source.set_property('location', args[1])
if os.environ.get('USE_NEW_NVSTREAMMUX') != 'yes': # Only set these properties if not using new gst-nvstreammuxstreammux.set_property('width', 1920)streammux.set_property('height', 1080)streammux.set_property('batched-push-timeout', 4000000)streammux.set_property('batch-size', 1)
# 设置nvinfer元件中的属性config-file-path, 通过设置配置文件来设置nvinfer元件的所有必要属性
pgie.set_property('config-file-path', "dstest1_pgie_config.txt")此时。管道、元件都已经创建并赋值。现在需要把创建好的元件按照顺序,需要全部添加到管道中。
print("Adding elements to Pipeline \n")
# 这里sink已经被判断过,是否需要使用transform
pipeline.add(source)
pipeline.add(h264parser)
pipeline.add(decoder)
pipeline.add(streammux)
pipeline.add(pgie)
pipeline.add(nvvidconv)
pipeline.add(nvosd)
pipeline.add(sink)
现在,我们需要通过pad(衬垫)来将元件连接起来。Pad是一个element的输入/输出接口,分为src pad(生产衬垫)和sink pad(消费衬垫)两种。在element通过pad连接成功后,数据会从上一个element的src pad传到下一个element的sink pad然后进行处理。
# we link the elements together
# file-source -> h264-parser -> nvh264-decoder ->
# nvinfer -> nvvidconv -> nvosd -> video-renderer
print("Linking elements in the Pipeline \n")
# 先将输入部分连接
source.link(h264parser)
h264parser.link(decoder)# decoder和streammux通过pad(衬垫)来将元件连接起来
# 在element通过pad连接成功后,数据会从上一个element的src pad传到下一个element的sink pad然后进行处理
# 生产pad
srcpad = decoder.get_static_pad("src")
if not srcpad:sys.stderr.write(" Unable to get source pad of decoder \n")# 消费pad
sinkpad = streammux.get_request_pad("sink_0")
if not sinkpad:sys.stderr.write(" Unable to get the sink pad of streammux \n")srcpad.link(sinkpad)# 连接剩余元件
streammux.link(pgie)
pgie.link(nvvidconv)
nvvidconv.link(nvosd)
nvosd.link(sink)
获取管道的消息总线,添加消息监控器。其中bus_call 是消息处理函数
bus = pipeline.get_bus()
bus.add_signal_watch()
bus.connect("message", bus_call, loop)
让我们添加探测来获得生成的元数据的信息。我们添加探测到 osd 元素的接收单元,因为到那时,缓冲区已经获得了所有的元数据。在下文我们会介绍osd_sink_pad_buffer_probe函数,这里先了解此函数的作用就是获取到所有元数据信息,在此基础上画框和打印文字。
# 添加探测来获得生成的元数据的信息,
# 添加探测到 osd 元素的接收单元,因为缓冲区已经获得了所有的元数据
osdsinkpad = nvosd.get_static_pad("sink")
if not osdsinkpad:sys.stderr.write(" Unable to get sink pad of nvosd \n")
# osd_sink_pad_buffer_probe函数的作用就是获取到所有元数据信息,在此基础上画框和打印文字
# 具体介绍参考上面
osdsinkpad.add_probe(Gst.PadProbeType.BUFFER, osd_sink_pad_buffer_probe, 0)所有准备工作都做好之后,就可以通过将管道的状态切换到PLAYING状态,来启动整个管道的数据处理流程:
# start play back and listen to events
print("Starting pipeline \n")
# 将管道的状态切换到PLAYING状态,来启动整个管道的数据处理流程
pipeline.set_state(Gst.State.PLAYING)
try:# 进入主训练, 等待管道遇到错误或者EOS而终止loop.run()
except:pass
# cleanup
pipeline.set_state(Gst.State.NULL)
osd_sink_pad_buffer_probe函数
这个函数的作用就是提取从 osd接收器接收到的元数据 ,并更新绘图矩形、对象信息等的参数。阅读这部分,需要了解DeepStream中的数据结构,可以阅读官方文档,看**这里**。 但我在阅读官方文档过程中发现文中绘制的数据结构有点过时,和源码中的不完全对应。我自己重新绘制了一个,见下图。
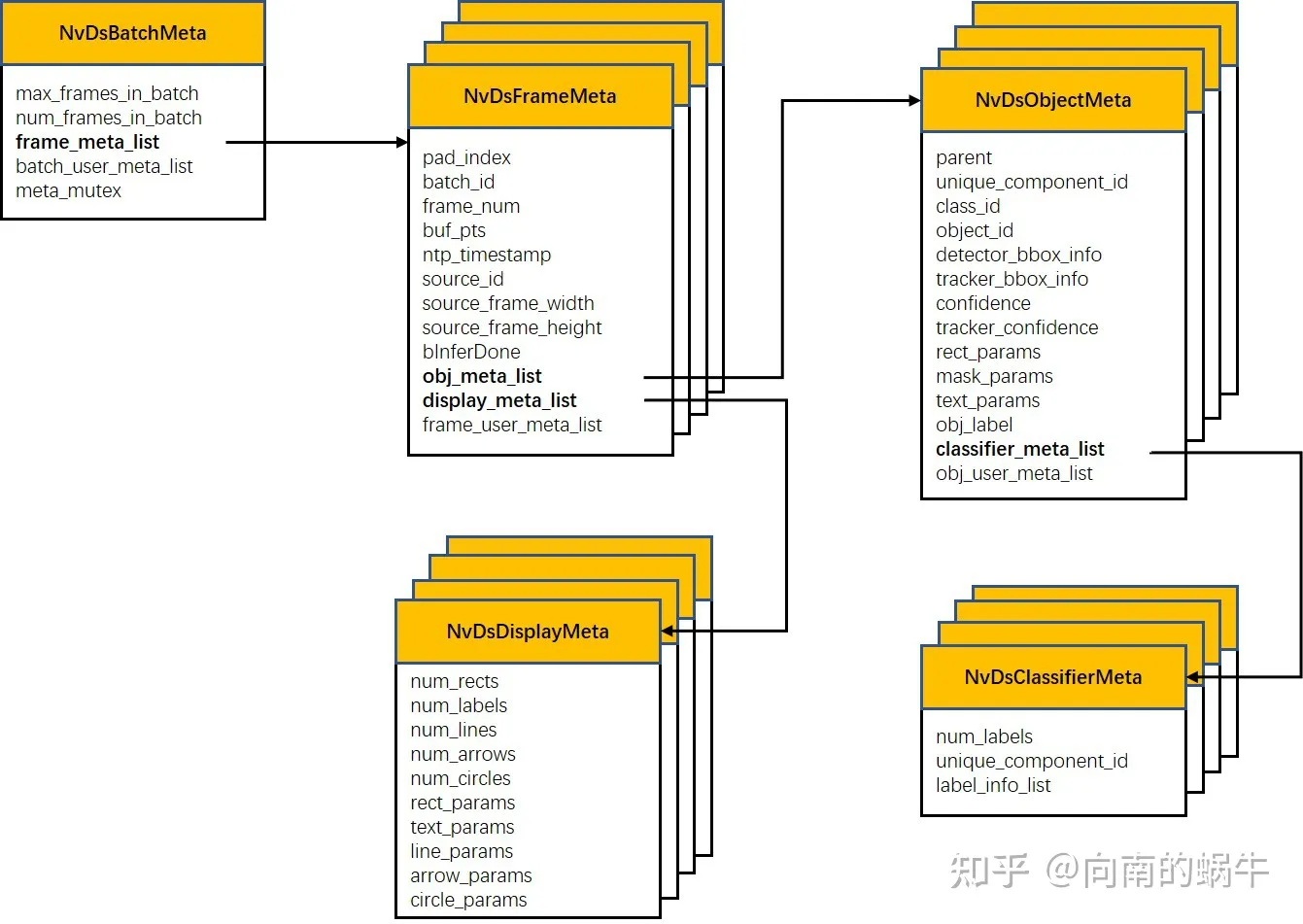
def osd_sink_pad_buffer_probe(pad, info, u_data):frame_number = 0num_rects = 0gst_buffer = info.get_buffer()if not gst_buffer:print("Unable to get GstBuffer ")return# Retrieve batch metadata from the gst_buffer# Note that pyds.gst_buffer_get_nvds_batch_meta() expects the# C address of gst_buffer as input, which is obtained with hash(gst_buffer)# 函数 gst_buffer_get_nvds_batch_meta()作用是 从 Gst Buffer 中提取 NvDsBatchMetabatch_meta = pyds.gst_buffer_get_nvds_batch_meta(hash(gst_buffer))# 对batch_meta 中的frame_meta_list进行遍历; frame_meta_list列表的长度是num_frames_in_batchl_frame = batch_meta.frame_meta_listwhile l_frame is not None:try:# Note that l_frame.data needs a cast to pyds.NvDsFrameMeta# The casting is done by pyds.NvDsFrameMeta.cast()# The casting also keeps ownership of the underlying memory# in the C code, so the Python garbage collector will leave# it alone.frame_meta = pyds.NvDsFrameMeta.cast(l_frame.data)except StopIteration:break# Intiallizing object counter with 0.obj_counter = {PGIE_CLASS_ID_VEHICLE: 0,PGIE_CLASS_ID_PERSON: 0,PGIE_CLASS_ID_BICYCLE: 0,PGIE_CLASS_ID_ROADSIGN: 0}frame_number = frame_meta.frame_numnum_rects = frame_meta.num_obj_metal_obj = frame_meta.obj_meta_list# 单帧的obj_meta_list进行遍历while l_obj is not None:try:# Casting l_obj.data to pyds.NvDsObjectMetaobj_meta = pyds.NvDsObjectMeta.cast(l_obj.data)except StopIteration:break# 判断目标检测框的类别如果是0(0是汽车的类别标签),那么车辆数+1,目标检测框数+1.# 如果是2(0是行人的类别标签),那么行人数+1,目标检测框数+1.obj_counter[obj_meta.class_id] += 1obj_meta.rect_params.border_color.set(0.0, 0.0, 1.0, 0.8) # 0.8 is alpha (opacity)try:l_obj = l_obj.nextexcept StopIteration:break# Acquiring a display meta object. The memory ownership remains in# the C code so downstream plugins can still access it. Otherwise# the garbage collector will claim it when this probe function exits.display_meta = pyds.nvds_acquire_display_meta_from_pool(batch_meta)# 设置display_meta的text_params属性display_meta.num_labels = 1py_nvosd_text_params = display_meta.text_params[0]# Setting display text to be shown on screen# Note that the pyds module allocates a buffer for the string, and the# memory will not be claimed by the garbage collector.# Reading the display_text field here will return the C address of the# allocated string. Use pyds.get_string() to get the string content.py_nvosd_text_params.display_text = "Frame Number={} Number of Objects={} Vehicle_count={} Person_count={}".format(frame_number, num_rects, obj_counter[PGIE_CLASS_ID_VEHICLE], obj_counter[PGIE_CLASS_ID_PERSON])# Now set the offsets where the string should appear# 设置文本在画面中的x,y坐标(分别是相对于画面原点的偏移量)py_nvosd_text_params.x_offset = 10py_nvosd_text_params.y_offset = 12# Font , font-color and font-size# 设置文本的字体类型、字体颜色、字体大小py_nvosd_text_params.font_params.font_name = "Serif"py_nvosd_text_params.font_params.font_size = 10# set(red, green, blue, alpha); set to Whitepy_nvosd_text_params.font_params.font_color.set(1.0, 1.0, 1.0, 1.0)# Text background color# 设置文本的背景颜色py_nvosd_text_params.set_bg_clr = 1# set(red, green, blue, alpha); set to Blackpy_nvosd_text_params.text_bg_clr.set(0.0, 0.0, 0.0, 1.0)# Using pyds.get_string() to get display_text as stringprint(pyds.get_string(py_nvosd_text_params.display_text))# 将display_meta 信息添加到frame_meta信息中pyds.nvds_add_display_meta_to_frame(frame_meta, display_meta)try:l_frame = l_frame.nextexcept StopIteration:breakreturn Gst.PadProbeReturn.OK