
SIMBAR论文精读
SIMBAR:用于自动驾驶视觉任务的有效数据增强的基于单个图像的场景重新照明
Single IMage-BAsed scene Relighting
摘要
真实世界的自动驾驶数据集由道路上不同驾驶的信息汇总而成。能够以可控的方式将捕捉到的场景重新照亮到不可见的照明条件,这提供了一个机会,可以用更丰富的照明条件来增强数据集,这与现实世界中遇到的情况类似。本文提出了一种新的基于图像的重新照明管道SIMBAR,它可以以单个图像作为输入。据我们所知,目前还没有利用单个图像中的显式几何表示进行场景重新照明的工作。我们提出了与先前多视图场景重新照明基线的定性比较。为了进一步验证和有效地量化利用SIMBAR进行自动驾驶视觉任务数据增强的效益,SIMBAR上的CenterTrack增强的KITTI实现了93.3%的多目标跟踪精度(MOTA),与原始KITTI上的CenterTrack 85.6%的基线MOTA相比,相对提高了9.0%,这两个模型都是从零开始训练并在虚拟KITTI中测试的。有关更多详细信息和数据集,请访问我们的项目网站(https://simbarv1.github.io).
1、介绍
光照条件缺乏多样性是一个已知的问题,这与手动收集的真实世界自动驾驶数据集有关[1,3,15,19]。例如,KITTI[19]只在中午拍摄视频序列,不同序列的光照和阴影条件相似。较新的数据集[33,39,61],如BDD100K[61],在多样性方面相对较好,并且在一天中的多个时间内都能捕获图像。尽管如此,在从同一驱动器收集的图像之间,照明条件的变化很小。此外,试图获取所有类型照明条件的数据在时间和金钱方面都是不可能的。
这种照明条件的多样性以及场景中存在的阴影,往往是成功部署安全关键型自动驾驶应用感知模型的关键障碍。在有限的照明条件下训练的模型无法概括现实世界中遇到的过多的照明条件[27,29]。以可控方式重新照亮现有数据集的能力为开发改进的感知模型提供了机会。
然而,在没有深度传感器的情况下,场景重新照明是一项极其困难的视觉任务。它隐含地包括三个主要子任务:阴影检测[10,26,55],移除[24,25,55]和插入[63]。其中,阴影移除和插入最具挑战性,因为阴影与源对象几何测量紧密结合[2,16]。这种耦合使得在没有对场景的强大3D几何理解的情况下,很难将阴影与其父对象分离[4,8,21]。为了解决这一问题,大多数现有场景重新照明方法依赖于源照明条件的多个相机视图来估计3D场景几何[44,51,64]。可以处理单个图像的相对较少的现有方法是基于生成对抗网络(GAN)[6]。已知GAN难以训练[32,40],控制不稳定性有限[54],并且经常产生与场景几何结构物理不一致的结果[17]。据我们所知,目前还没有使用单个输入图像进行可控场景重新照明的工作。

图1. 输入图像(左)与SIMBAR重新发光输出(中、右)相对显示。SIMBAR合成了(a)(b)Div2k、(c)BDD100K和(d)KITTI的两种照明变体
本文提出了一种新颖的、基于单图像的场景重照明流水线SIMBAR。它以一张图像作为输入,并为各种太阳位置和天空天顶生成relit版本,如图1所示。前两行显示Div2k[1]的relit结果。Div2k是一个互联网抓取的数据集,包含各种各样的对象类的图像,SIMBAR能够有效地重新点燃这些图像。第一行显示了具有复杂结构的室外场景的天空颜色、阴影颜色、一致投射阴影位置和光线强度的真实变化。第二排是具有挑战性的低光沙漠场景。SIM BAR清晰地去除了前景中岩石的现有硬投影阴影,并为所提供的太阳角度逼真地重铸几何一致的阴影。此外,地平线上的山地景观也得到了有效的保护。第三行和第四行还分别显示了BDD100K的KITTI道路驾驶场景和隧道/地下通道场景的几何一致和视觉逼真的relit版本。最值得注意的是BDD100K示例中隧道的硬阴影和KITTI示例中的两辆车的变化。
SIMBAR由两个主要模块组成:(i)几何估计和(ii)图像重新照明。几何体估计模块负责计算场景网格代理和照明缓冲区。我们受到WorldSheet[23]的启发,使用外部深度网络来获得场景网格。请注意,WorldSheet是一种新颖的视图合成管道,不具有重新照明的目的。图像重新照明模块的灵感来源于先前的多视图场景重新照明工作,使用几何感知网络[44],简称MVR。第3.1节简要概述了基于Single图像的场景几何估计和MVR,然后在第3.2节中详细描述了SIMBAR的管道描述。我们的工作在目标和总体管道结构方面最接近MVR。因此,使用开箱即用的MVR及其改进版本MVR-I进行场景重新照明比较,在第3.4节中,我们对视图有限的自动驾驶数据集的MVR进行了改进。总之,与MVR/MVR-I将同一场景的多个图像作为输入相比,SIMBAR提供了更加逼真和几何一致的重新照明图像,即使它将单个图像作为输入。
关于场景重新照明的所有现有工作的另一个主要限制是缺乏对增强视觉数据集中场景重新照明效果的定量评估。在缺乏这种度量的情况下,无法确定任何场景重新照明方法的真实适用性和有用性。为了解决这一问题,在第4节中,我们使用最先进的目标检测和跟踪网络CenterTrack[66]进行了基于图像重照明的数据增强实验。第4.1节详细概述了我们的实验设置。我们训练了三种不同的CenterTrack模型:(i)原始KITTI跟踪数据集,其中包含中午捕获的21个真实世界序列;(ii)用MVR-I relit序列扩增KITTI;和(iii)用SIMBAR relit序列扩增KITTI。所有模型都在虚拟KITTI(vKITTI)[18]上进行了测试,该模型由多种光照条件下真实KITTI序列的克隆组成。第4.2节显示,使用重新照明的KITTI图像(来自MVR-I或SIMBAR)增强的CenterTrack模型明显优于基线CenterTrack。具体而言,在KITTI上训练的中心跟踪模型(使用SIMBAR增强)实现了93.3%的最高多目标跟踪精度(MOTA),比85.6%的基线MOTA相对提高了9.0%。该模型还实现了94.1%的最高多对象检测精度(MODA),再次比86.4%的基线MODA相对提高8.9%。
综上所述,本文的主要贡献如下:
一种新的基于单视图图像的场景重新照明管道,称为SIMBAR,它提供了照明控制的不稳定性,而不需要多视角图像。
通过调整密集预测变换器单深度模型和更好地表示远处背景对象,基于单个图像的几何估计。
MVR[44]的一个改进版本,称为MVR-I,在生成的网格中具有更少的伪影和更平滑的表面,用于视图有限的道路驾驶场景,从而生成更逼真的逼真图像。
在多个自动驾驶数据集(如KITTI[19]和BDD100K[61])上,使用MVR、MVR-I和SIMBAR对场景重新照明结果进行定性评估和比较。
使用 SIMBAR 和 MVR-I 对流行的KITTI 2D跟踪数据集进行挖掘的有效性的定量评估,用于使用CenterTrack同时进行目标检测和跟踪。
2、相关工作
我们的工作与新颖视图合成[36,49,56]、3D重建[9,58,59]和基于物理的可微渲染[30,43]等领域密切相关。鉴于重新照明任务和场景几何之间的直接联系[12,62,67],我们将相关工作分为两大类:(i)学习几何先验并将其编码为模型的隐式方法;以及(ii)利用输入场景的多个视图生成3D网格以应用渲染和图像处理技术的显式方法。虽然显式方法提供了更好的可控性和几何一致的阴影,但其多视图前提条件限制了其在大多数自动驾驶数据集中的应用。这是由于前向汽车摄像头视野有限的独特挑战,以及不断移动的汽车和行人的高场景复杂性。我们的工作属于显性范畴,同时利用了来自隐性方法的见解。
2.1 使用隐式几何表示
生成对抗网络(GAN)[22]和神经辐射场(NeRFs)[37]都探索了场景再照明。与GAN的典型情况一样,[6]中的阴影操纵网络难以保持几何一致性,且难以训练,从而导致保守的再照明效果。这也适用于关注图像到图像转换而忽略几何先验的GAN[11,17]。基于NeRF的新视图合成方法最近的成功自然也导致了它们在场景重新照明任务中的应用。NeRF不是查询显式场景几何体,而是将场景编码到多层感知器(MLP)[35]中,该感知器将观看方向和位置作为输入,以输出颜色和密度值,然后用于体积渲染[41,42]。在训练时,将静态场景的许多不同视图提供给网络以学习场景几何体。在测试时,使用输入的观看方向和位置来渲染具有精确照明和阴影的场景。最近的工作通过对表面材质和反射财产建模,将NeRF重新用于场景重新照明[5,51,64]。然而,由于每个场景都需要训练不同的模型,因此这些方法在应用于具有动态场景的自动驾驶数据集时面临着显著的计算障碍。
2.2 使用显式几何表示
将来自运动的结构与多视图立体(SFM+MVS)相结合是建模场景几何体的常用方法。它依赖于从单个感兴趣场景的不同视图捕获的图像之间的特征匹配。在应用SFM+MVS之后,束调整[53]可用于生成3D点云,如COLMAP[47,48]中的情况。点云允许应用传统的网格重建技术,例如Delaunay[7]或Poisson[31]重建,以生成场景的显式几何表示。利用几何先验的视觉任务,如新颖的视图合成,可以利用这种显式场景表示[46,60]。网格还可以应用于场景重新照明任务,如[44]所述。在他们的工作中,基于物理的渲染用于使用生成的网格来近似阴影位置,并使用额外的网络进行阴影细化。重新照明的结果真实且几何一致。然而,这种方法在应用于各种数据集方面受到严重限制。例如,有限的视图和动态场景导致网格重建失败[28]。在相对简单和受限的数据集(如人类肖像)的情况下,由于面部数据的结构高度相似,使用单个视图重新照明图像已经成功[38,65]。然而,户外场景数据集的情况并非如此,它包含更广泛的结构和内容[13]。
3、基于单个图像的场景重新照明
我们提出的管道SIMBAR将场景建模为3D网格,以明确表示场景几何体。然后,基于物理的渲染与阴影细化网络一起使用,以生成真实的阴影贴图。原始图像可以与目标阴影贴图合成,以形成最终的relit输出。这种方法弥补了现有作品在多视图场景重新照明方面的局限性,并且可以跨场景推广。
3.1 准备工作
3.1.1 基于单图像的场景几何估计
为了解决基于SFM+MVS的网格重建的多视图限制,我们受到WorldSheet[23]的启发,使用外部深度进行场景几何估计,以执行基于单个图像的网格重建。请注意,总体 WorldSheet 和 SIMBAR 管道的基本思想是完全不同的。World Sheet是一种可区分的渲染管道,针对新颖的视图合成进行了端到端的训练,而SIMBAR旨在通过各种阴影投射来操纵现有视图。
对于场景网格形成,外部深度预测被视为地面真实值,因此不需要预测x和y方向上的网格偏移。设zw,h为相应板材坐标(w,h)处的深度预测,xw,h和yw,h是从[0,1]开始的归一化设备坐标(NDC)空间中简单线性间隔的样本,相机位于原点。给定129×129的网格片的固定大小,对深度预测进行网格采样以说明分辨率的差异。对于FoV角θF,这给出了形成顶点坐标的以下方程:
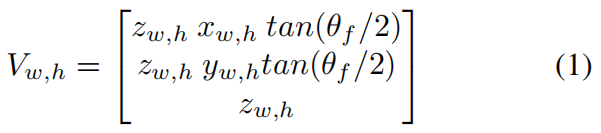
连接相邻顶点的网格边形成网格面[23]。然后使用拉普拉斯函数[50]对最终输出网格的面进行平滑。
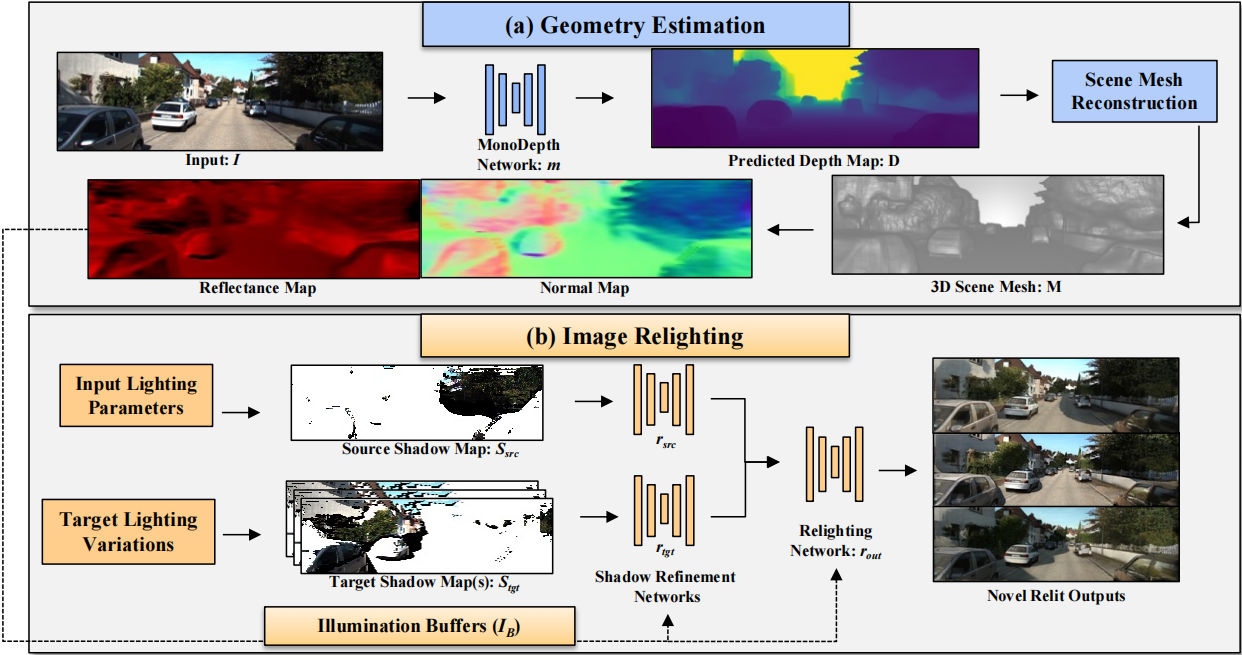
图2:(a) 几何估计组件:将单个输入图像I馈送到单目深度估计网络(m)。预测的深度图D用于使用等式1中的顶点坐标来形成场景网格。得到的顶点和面的集合形成3D网格M。使用M相对于相机姿势渲染一组输入缓冲区IB。 (b) 图像重新照明组件:利用估计的输入照明参数和所需的目标照明变化,生成源阴影图Ssrc和目标阴影图Stgt。阴影细化网络rsrc和rtgt分别细化阴影映射Ssrc和Stgt。最后,重新照明网络路由使用IB获取精细的阴影图,以生成最终的重新照明图像。
3.1.2 几何感知多视图重新照明
对场景几何先验和场景几何与照明效果之间的关系进行编码是向阴影去除和合成网络提供强信号的既定方法[37,44,64]。SIMBAR中的图像重新照明网络遵循MVR[44],其中除了源图像之外,还利用一组几何先验作为输入。生成一组输入缓冲区IB,由法线贴图、反射率贴图和重新定义的阴影贴图组成。法线贴图对每个像素处的曲面法线进行编码。反射率贴图是曲面法线和太阳方向之间的点积。为了获得精细化的阴影贴图,一组粗糙的RGB阴影贴图被用作两个阴影精细化网络的输入-一个用于源和目标照明条件。这些粗糙的RGB阴影贴图是从投射到场景的3D网格上的光线创建的,以生成阴影位置。对于与网格相交并投射阴影的每条光线,让mi表示相交点。mi的坐标可以被重新投影以找到对应的2D图像像素及其RGB值。后者在阴影贴图中编码,以创建RGB阴影贴图。编码与投射阴影的对象相对应的RGB值可以帮助阴影细化网络纠正3D网格重建所产生的错误,以便为重新照明网络生成最终的细化阴影贴图。
为了完成重新照明过程,将第三网络与阴影细化网络结合使用。所有这些都是在合成渲染数据上预先训练的。给定源和目标照明条件的输入图像和RGB阴影图,源和目标阴影再细化网络尝试细化阴影图以纠正网格构建中的错误。随后是最终的重新照明网络,该网络同时采用场景优先级和精细的阴影贴图来生成重新照明输出。
3.2 方法说明:SIMBAR
大多数现有场景重新照明方法[44,51,64]需要具有不同视点的多个图像。相比之下,SIMBAR利用单目深度估计来获得几何近似。SIMBAR是模块化的,具有两个不同的组件:几何估计和图像重新照明。整个管道如图2所示。几何估计模块(a)将场景表示为3D网格,这允许为图像重新照明模块(b)生成各种信息先验。这允许利用显式几何场景表示的单个基于图像的场景重新照明的新颖系统设计。
3.2.1 几何估计组件
SIMBAR中的几何估计模块从单个输入图像I生成3D场景网格M,如图2所示。这与MVR形成了直接对比,MVR依赖SFM+MVS[47,48]进行多视图场景重建。从单个图像I生成网格M所采取的步骤受到WorldSheet(参考第3.1.1节)的启发,但对网格重建进行了额外修改。
在SIMBAR中,使用外部预训练的单眼深度估计网络来提供用于生成场景网格的深度信息。这是因为当利用Worldsheet变体时,室外驾驶场景会提供更高质量的网格,该变体使用外部深度预测,而不是预测深度和网格偏移的完整端到端管道。这一观察是有意义的,因为对于WorldSheet训练模型,在端到端训练模式中,网格M没有直接损失。取而代之的是,超级视觉仅通过在最终的relit图像上的渲染损失获得。因此,预测的网格偏移可能不如使用外部深度网络获得的网格偏移在几何上准确。此外,我们还调整了新的单深度主干,以改进场景几何估计,从而实现重新照明。

图3。(a) 使用MiDaS v2.1,3D场景网格会错过细节,导致(b)没有创建突出的阴影。(c) 我们对DPT Hybrid的改进利用密集的视觉转换器捕捉远处的汽车物体,(d)创建逼真的阴影。
改进的单眼深度估计:
虽然WorldSheet使用MiDaS v2.1作为外部深度骨干,但我们已经试验了密集预测变换器(DPT)单深度模型[45])。图3显示,使用MiDaS v2.1深度预测,生成的网格M错过了远处的汽车对象,从而错过了可能投射阴影的编码结构细节。这一点在最上面一排的KITTI场景中尤其明显,在那里,远处的汽车物体并没有很好地被发现。为了解决这一限制,我们发现在DPT Hybrid Kitti(在Kitti上微调)中使用改进的密集视觉变换器有助于生成更详细的网格。
前景/背景场景分离:
如图2所示,对于给定的输入图像I,使用预训练的单眼深度估计网络来获得像素方向的逆深度值D。然后,使用这些值来通知平面场景网格的变形。我们观察到,在不同的尺度上对逆深度进行阈值化可以让我们关注不同的细节级别。
图4显示了具有不同水平的逆深度阈值的实验。对于800的高逆深度阈值,生成的墙表面相当接近相机和场景内容。这种设置可能适用于深度范围较低的场景,但在具有不同深度边界的不同户外场景中失败。这将导致过度阴影结果,其中假曲面在场景上投射自己的阴影。我们选择较低的逆深度阈值,因为这对应于距离相机位置更远的距离。这允许网格进一步向后延伸,并生成更干净的阴影。在具有较低逆深度阈值的网格M中,天空和地平线中较远的表面都得到了更好的表示。
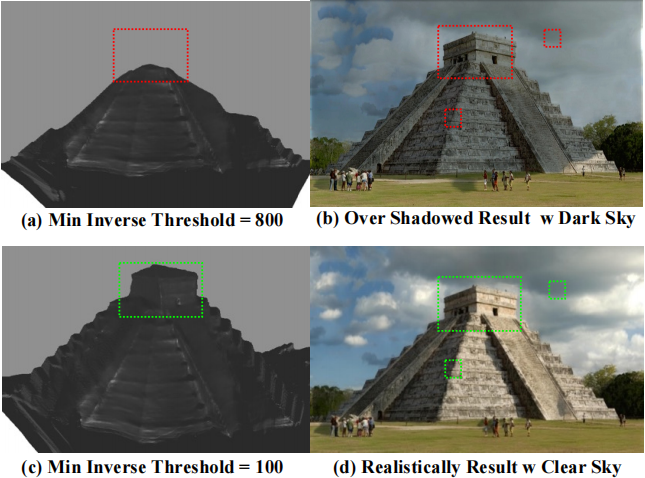
图4。(a) 对于最小反向深度800,场景网格在相应的阈值距离处形成平坦的垂直表面。这种现象被观察到是因为一堵平坦的浅灰色墙壁错误地切断了金字塔几何形状的顶部。(b) 此墙伪影在标记为“阴影过大”的重新照明图像中投射出一个巨大的阴影。(c) 使用100的最小反向深度有效地将墙边界推得更远,这为场景网格提供了更高级别的细节,从而产生(d)更逼真的清晰阴影效果。
3.2.2 图像重新照明组件
如图2所示,给定来自几何估计模块的场景网格M,将生成一组先验或输入缓冲,如第3.1.2节所述。它们作为输入被馈送到阴影细化网络(rsrc,rtgt)和随后的图像重新照明网络(rout)。我们选择使用MVR的预训练网络进行rsrc、rtgt和rout,因为尽管不同数据集的网格结构不完善,但它们的表现良好。此外,获得一组大而多样的高分辨率合成数据用于重新训练重新照明网络既耗时又成本高昂。因此,在SIMBAR中,我们专注于对单视图几何感知场景重新照明的新颖适应。
3.3 改进的MVR方法作为基线:MVR-I
开箱即用的MVR方法在单视图收集的自动驾驶数据集上失败。为了允许与强大的基线进行比较,我们为视野有限的道路驾驶场景优化了MVR,我们称之为MVR-I。我们使用MVR-I作为所有定性(第3.4节)和定量比较(第4.2节)的基线。

图5。RGB点云覆盖在为KITTI场景可视化生成的场景网格的顶部。使用开箱即用的MVR,使天空中的表面产生幻觉(a),从而产生幻影阴影(b),我们使用MVR-I(c)对其进行了改进,从而产生更逼真的图像重新照明结果(d)。
去除幻觉网格表面:
首先,我们发现在KITTI场景上运行MVR会在生成的网格中产生幻觉的天空表面,从而在地面上投射出相应的幻影阴影。这是因为SFM+MVS重建对输入图像中的选定3D特征点进行三角测量,在图像之间具有低的重投影误差。在图5中,注意(a)中导致天空中表面重建的三角点。这些产生幻觉的表面在天空中以及(b)中的圣像中的前景角上投射出显著的阴影。虽然阴影细化网络可以解决网格中的微小不准确[44],但显示的主要不准确会导致不现实的场景重新照明效果。为了解决这个问题,我们实施了一个简单但高效的修复。通过使用Detector2[57]对输入多视图图像进行分割,我们排除了(c)中出现在天空中的混淆因素,例如云以及天空本身。这解决了天空中产生幻觉的网格表面和相应的幻影阴影(d)的问题。
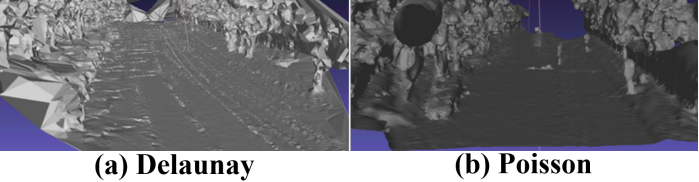
图6。(a) Delaunay曲面重建对噪声很敏感,会导致三角形伪影。(b) 泊松重建网格具有更平滑的表面。
改进的曲面重建:
第二个改进是用泊松曲面重建算法[31]代替用于网格生成的Delaunay曲面重建算法[7]。图6(左)显示了Delaunay算法导致了有噪声的网格,尤其是对于地面。同一场景的泊松曲面重建(右)可减少成角度的边,并使道路和树曲面整体更平滑。
这两种修复的自然结果是更现实的重新照明结果,如图5(d)所示。
3.4 场景重新照明结果
MVR和MVR-I都需要场景的多个视点,以使用SFM+MVS生成近似的3D网格。这种方法在静止的自我车辆捕获的视频序列中失败,因为在捕获的序列中缺少多个视点。这是SFM+MVS的一个已知限制,这导致使用MVR-I在KITTI帧中渲染许多透明阴影。这可以在图7的顶行中观察到。

图7。分别来自KITTI和BDD100K上的MVR-I(a)(c)和SIMBAR(b)(d)的重照明结果。
相比之下,SIMBAR提供了明显更真实和几何一致的重新照明结果,如图7(b)和(d)所示。虽然MVR-I无法从KITTI(顶部)和BDD100K(底部)逼真地重新照亮道路驾驶场景的图像,但SIMBAR的重新照明结果在目标阴影方向和天空颜色方面始终更加逼真。然而,有一些强烈的投射阴影残留无法清除干净。
3.5 限制
完全遮挡:
通过我们在几何估计模块中提出的改进(参见第3.2.1节),生成的网格有了显著的改进,导致前景对象的更多表面细节和背景对象的更好包含。然而,单目深度方法的自然缺点是排除了完全遮挡的对象。虽然部分遮挡的对象网格误差可以通过阴影细化网络进行校正,但完全遮挡的对象当前存在阴影移除问题。如果没有包含对象的附加视图,网格无法表示对象,但在真实输入图像中,对象仍然可以提供阴影。我们发现,在使用单个视图源时,由于缺少对象上的上下文,这有时会导致阴影移除中的阴影残留
场景网格操纵:
使用低反阈值生成天空对象,作为地平线上更远的墙表面(见图4),理想情况下,我们希望通过场景网格操作移除平坦的墙表面,以实现更稳健的场景网格分离。为了实现场景中单个对象的更好的几何欠平衡以及对场景重新照明和阴影操纵的更精确控制,另一种优化可以是使用神经网络(如mesh R-CNN[20])利用3D网格预处理。我们目前使用3D网格作为几何表示,不建模特定的曲面财产。进一步的建模可以实现真实的光照效果,这对镜面反射很重要。
论文地址
https://arxiv.org/pdf/2204.00644.pdf
官方详细介绍
https://simbarv1.github.io/
个人总结
这个一篇数据集增强--光照条件的论文,个人之前在这个方向上没有接触过,因此这篇论文整体没太理解,如果希望理解透彻建议将这个方向的论文整体再看一下