
Multimodal Emotion-Cause Pair Extractionin Conversations
对话中的多模态 情绪-原因对 的提取
论文题目(Title):Multimodal Emotion-Cause Pair Extraction in Conversations
研究问题(Question):情绪原因提取,以及情绪原因对提取
研究动机(Motivation):现有对话情绪识别的工作中缺少情绪原因的分析
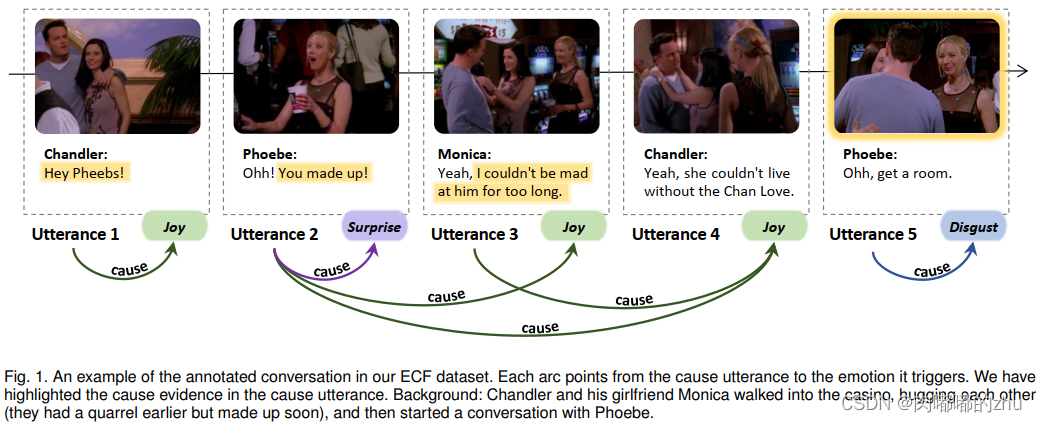
主要贡献(Contribution):
1. 提出对话中情绪原因对的提取任务Multimodal Emotion-Cause Pair Extraction(MECPE);
2. 以情景喜剧《老友记》为来源 ,构建了一个多模态情感原因数据集(ECF)。
研究思路(Idea):
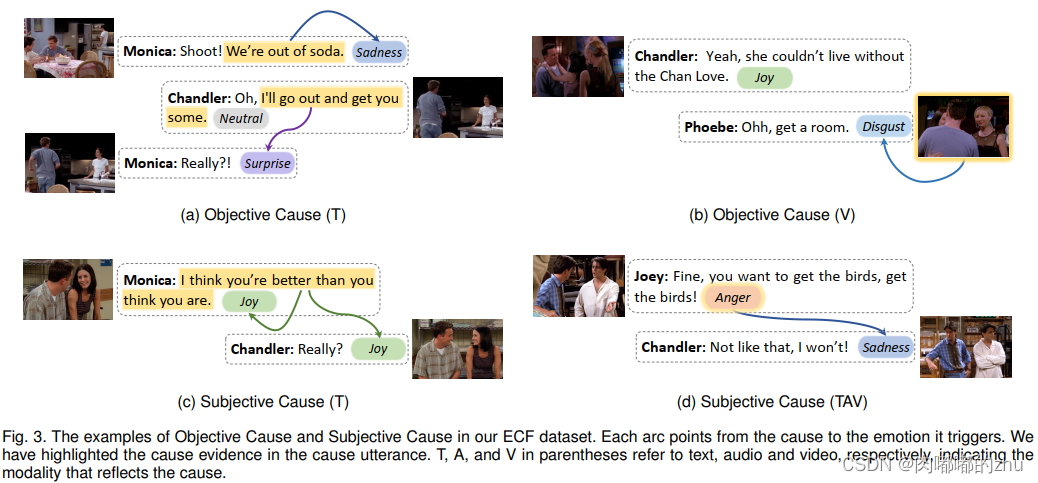
任务1:多模态情绪-原因对提取 (MECPE),分为主观原因和客观原因。
任务2:多模态情绪-原因对提取 情绪类别(MECPE-Cat),如图3,哪个对话造成了哪个情绪的产生。
研究方法(Method):
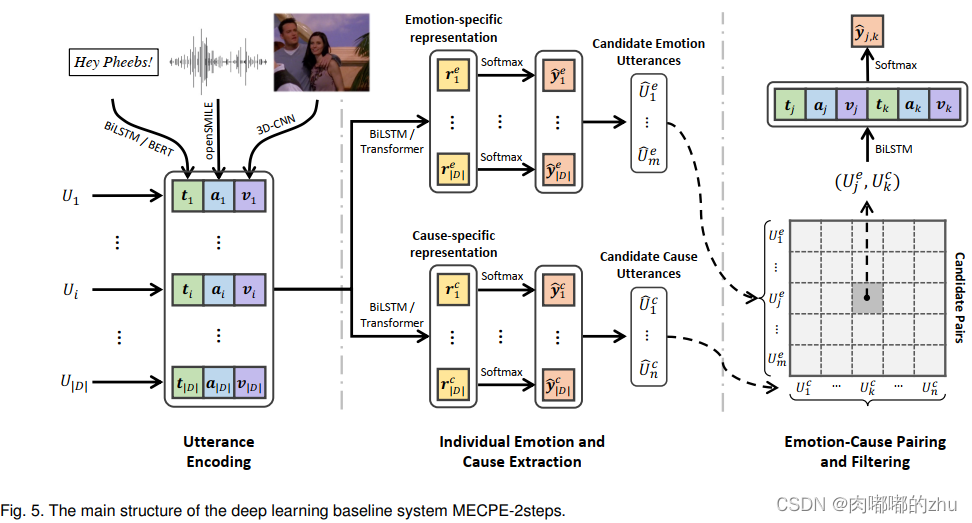
首先基于训练好的情感分类器识别情绪话语,然后根据两种相对位置(即, -2, -1, 0)的先验分布,对一个情绪的原因话语进行抽样。
C-Bernoulli:基于多变量伯努利分布假设,我们独立地对每个相对位置进行二元预测,以确定其对应的话语是否是原因话语;
文本:用预先训练好的300维GloVe向量初始化每个标记,并将它们输入一个带有标准注意机制的BiLSTM编码器,然后获得每个话语的文本特征。除了BiLSTM之外,还使用预先训练好的BERT作为基本的单词编码器,并将每个话语独立地输入其中。
音频:基于INTERSPEECH 2009情感挑战特征集,通过openSMILE工具包提取6373维声学特征;
视频:应用了一种3D-CNN网络,命名为C3D,利用深度3D ConvNet学习时空特征,从每个话语的视频中提取128维的视觉特征vi。具体来说,我们从每个视频中采样16帧,分辨率为171 × 128,并将它们馈送到C3D网络中提取a4096维视频描述符,然后用线性层进行降维。
研究过程(Process):
1.数据集(Dataset):ECF数据集
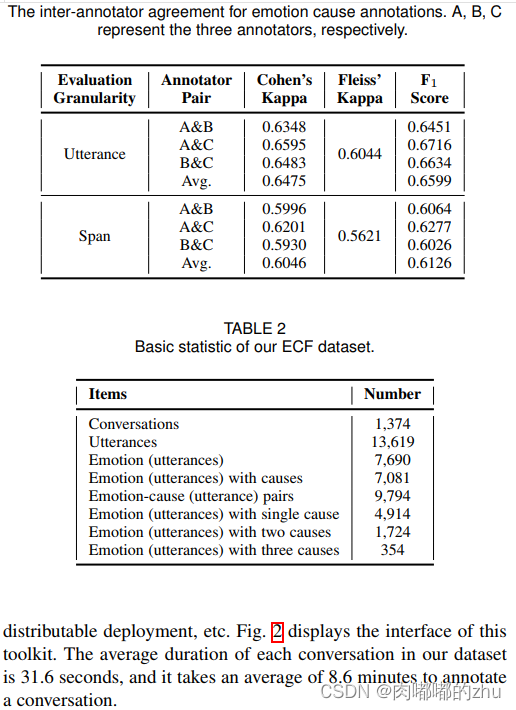
2.评估指标(Evaluation)

3.实验结果(Result)
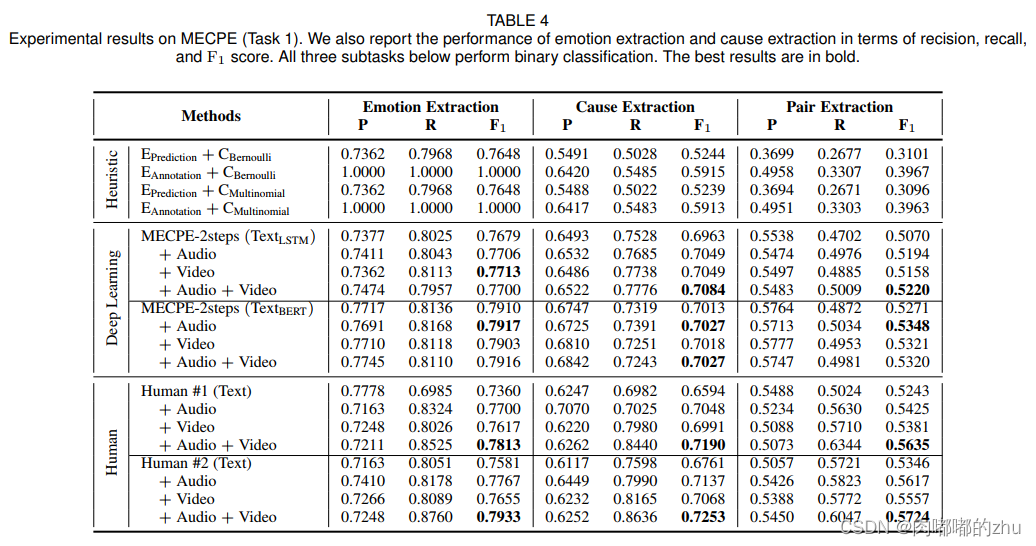
总结(Conclusion):MECPE是一项具有挑战性的任务。这项工作只是对这项任务的初步研究。提议的 两个基线系统有很大的改进空间。虽然多模态特征被证明对 MECPE任务是有效的,但增加是相当有限的。