
从一致性/debias角度考虑推荐优化问题(排序部分 四 《参数的一致性》)
在排序工作中,我们也经常遇到不同的一致性需求,关于排序一致性,我们往往需要考虑几个方面:《样本的差异》,《特征的差异》,《模型参数差异》,《目标差异》,《场景融合的差异》。当然他们之间并不是完全割裂的,譬如样本的差异,往往也涉及到模型参数的调整。这里为了便于说明,做了这么几个简单区分。
参数的一致性,目前的常见的方式一般通过通过先验或者后验的方式,验证了某一属性下(用户群,消费,预估目标,domian),模型存在严重不一致的问题,再通过个性化的参数来对模型进行调整。
比如以下例子:
1,《D2Q:Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation》D2Q认为不同物理时长视频的空间分布不一致,并且优势分布在消费过程中会不断强化自身的优势,形成因果loop,如下图1。
然后D2Q根据时长对不同的视频样本进行了划分,每个时长划分里使用独立的子预估模型参数,如下图2a,或者个性化的预估参数调整,如下图2c,以消除了优势分布带来的偏差,带来了性能的提升。
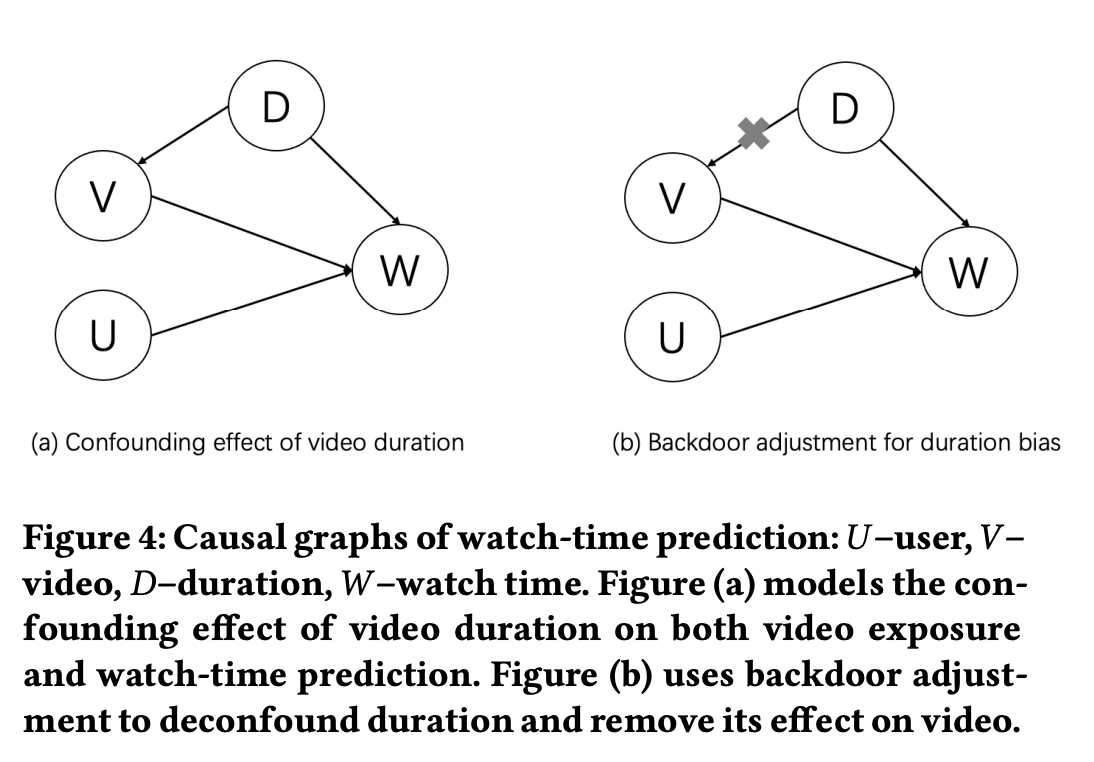
图1
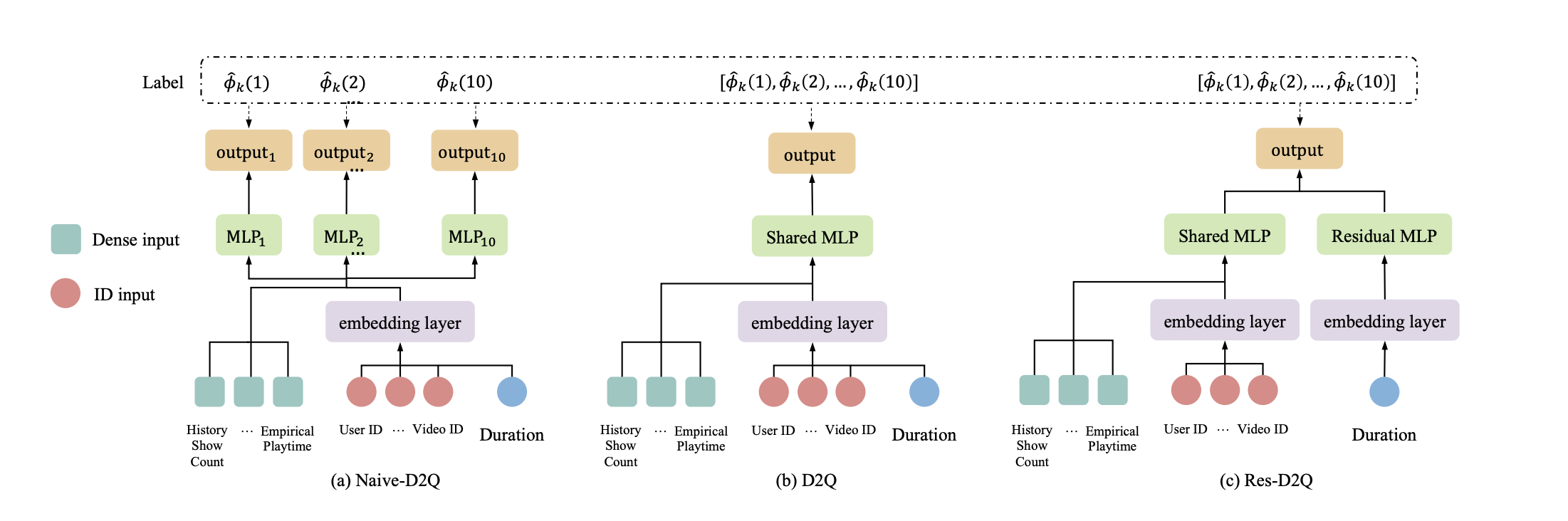
图2
2,《ODMN:Billion-user Customer Lifetime Value Prediction: An Industrial-scale Solution from Kuaishou》
ODMN认为在LTV(Customer Life Time Value ) 分布上存在大量分布不一致问题,如下图3所示,又因为对LTV的预估多数用的是mse loss,mse loss采用的是平方项,对较大值比较敏感,导致各种长尾分布预估效果较差。所以ODMN也根据LTV值分布对样本进行了分桶,然后把分桶作为分类标签,让模型学习样本属于哪个桶,最后再通过LTV值对每个桶内ODMN做了等频细分。如下图4。最后再划分的不同分布桶里使用独立的子预估模型参数,实现了预估精度的提升。
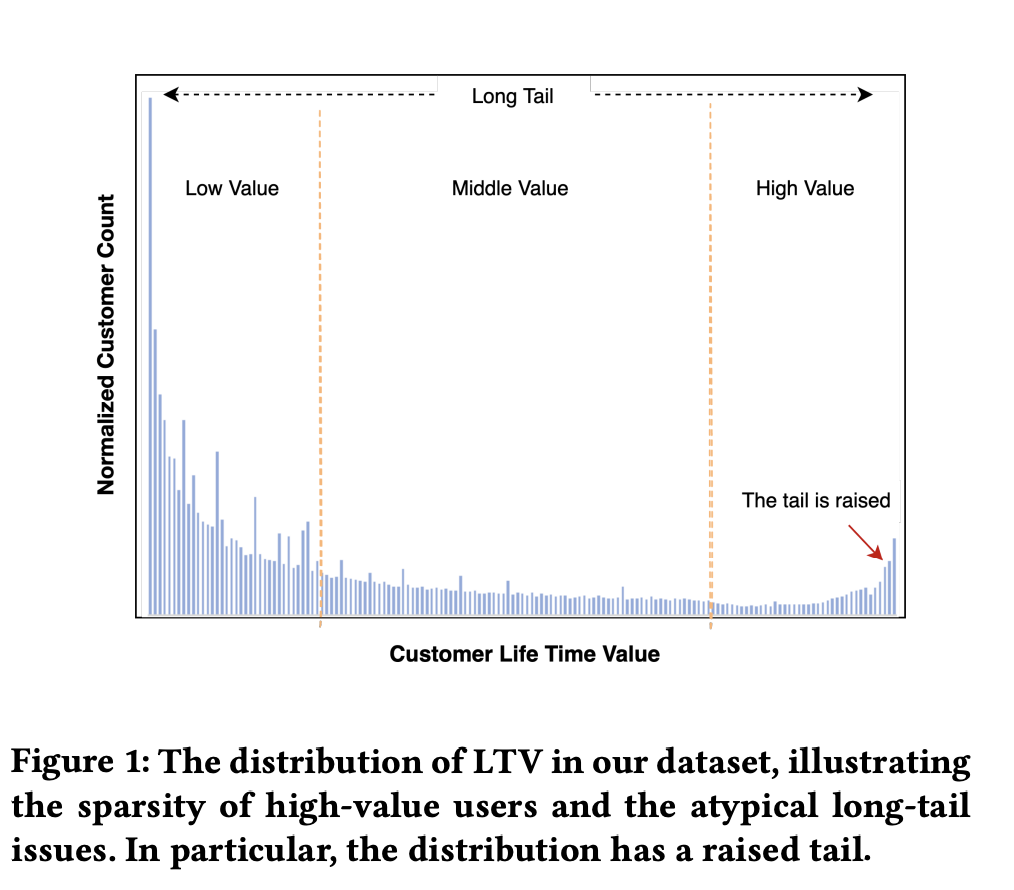
图3
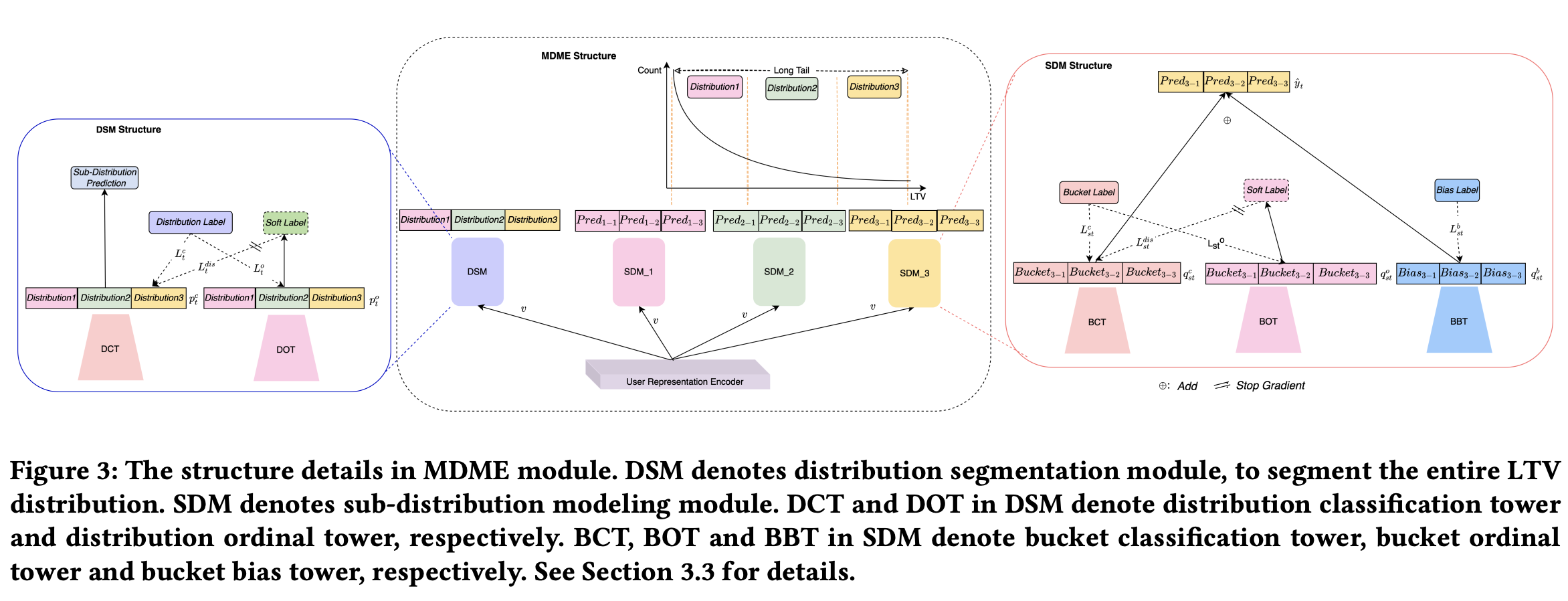
图4
3, 《POSO: Personalized Cold Start Modules for Large-scale Recommender Systems》
POSO认为不同的用户群体消费分布不同,如下图五。然后poso设计了一种gating的方式来针对不同的用户群体调整模型的参数图六。并且poso对模型参数调整的公式进行了简化,并给出了详细的推导,并证明了POSO可以集成到许多现有模块中,计算开销可以忽略不计。可以很方便的融合进现有的大规模的推荐系统
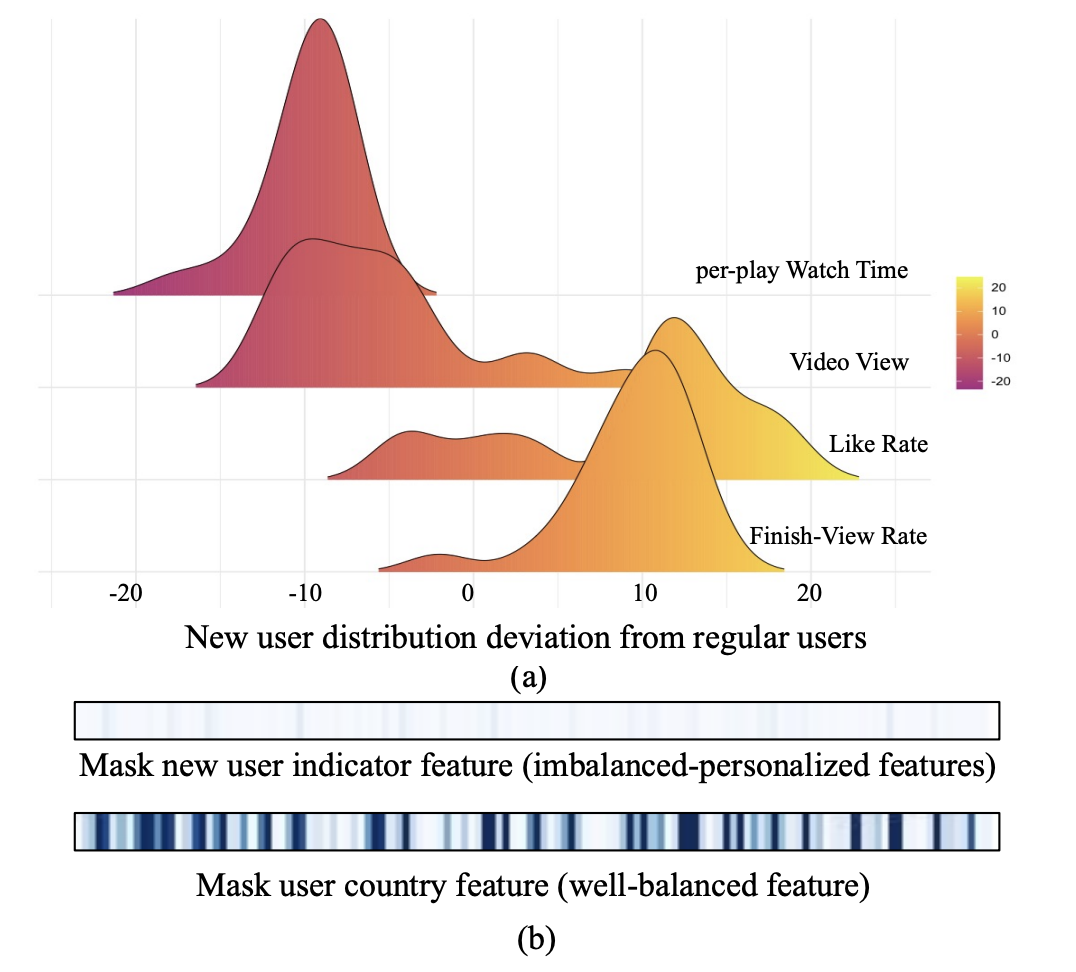
图五
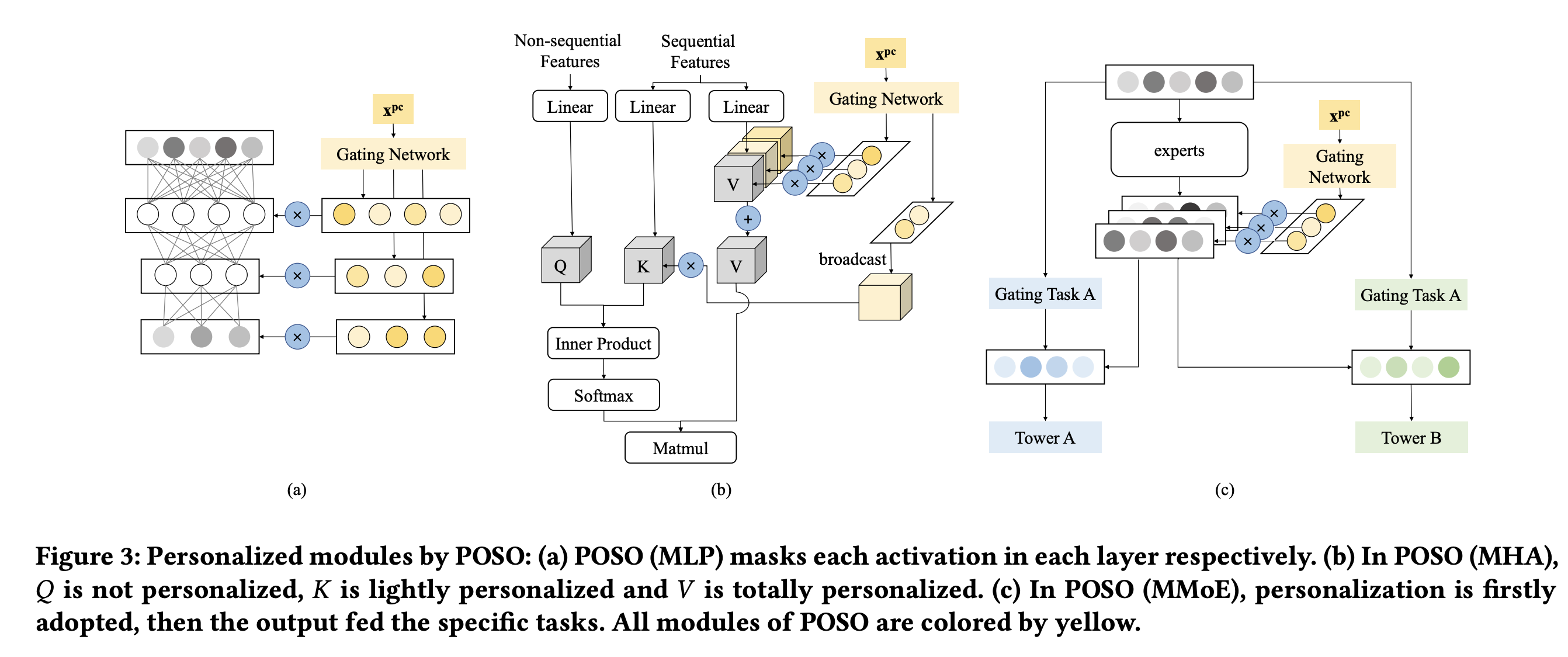
图六
4,《STAR:One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》
star认为一个大型商业平台通常包含多个域比如顶部栏框和猜你喜欢页图七,然而单一的模型很难捕捉到各种模型的特征域和服务好所有域。
所以star设计了一个个性化的domain适应模型。star对模型主要做了三块domain的个性化,第一是Partitioned Normalization,对每个domain的数据做了domain里的batch normal。第二是针对每个domian做了参数的个性化如下图八。第三是对每个domian做了辅助网络,把特征输入到logit上,更直接的影响了最终预测。
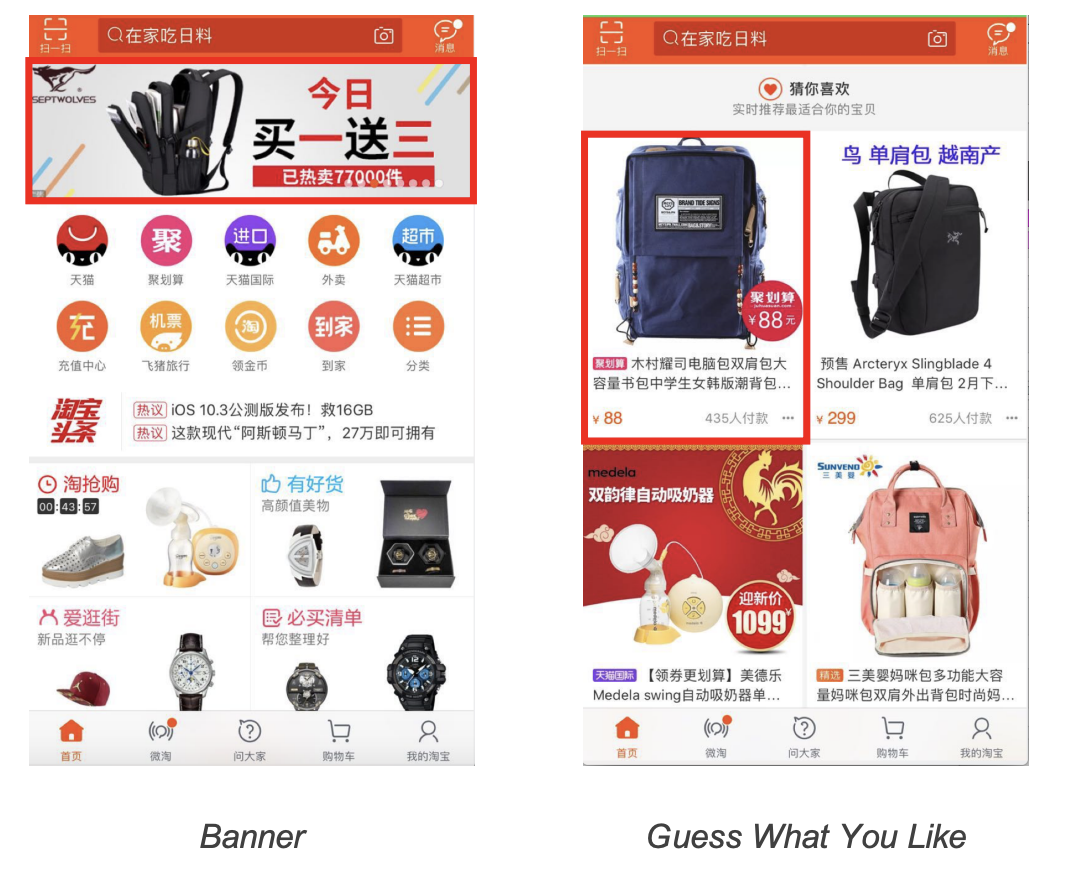
图七
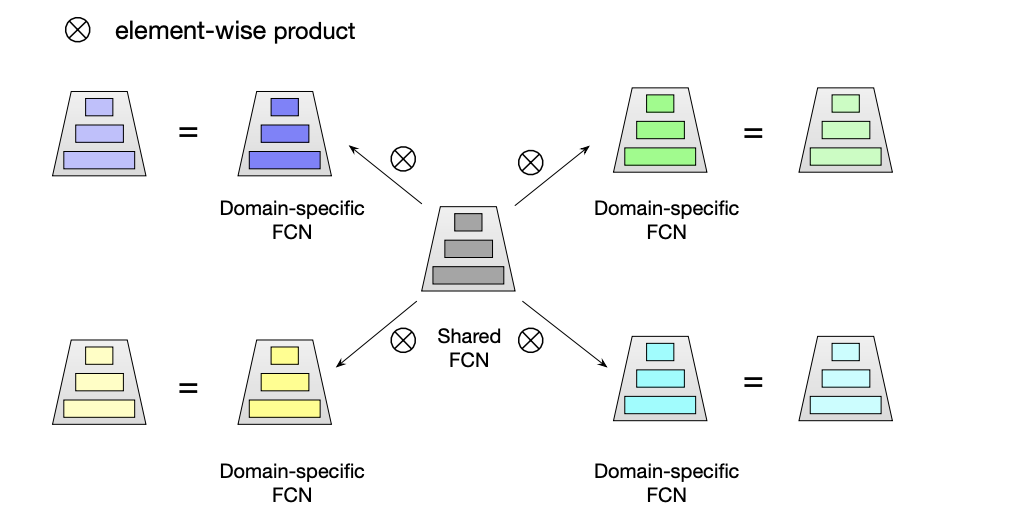
图八
可以看到,以上这些模型,有差异也有共同点。首先都有个强假设,或者验证,某个属性下存在分布的差异,带来了模型预估的偏差,然后用不同的方式对模型的参数,在模型的不同位置做个性化调整。
他们的差异可以归结为几个方面:
一,作用位置,当然一般个性化参数调整都是dense部分,因为这部分参数量较少,对模型大小影响较小,这里说的作用位置差异主要指dense部分更上层或者下层。
全部都作用肯定是影响最大的,如果只能选择一部分影响,到底是头部好还是底部好呢,这里不同的实践给出的结论也不太一样,有的场景认为作用在更上层效果更好,因为影响更直接,而且使用到的参数量也更少,比如star模型的辅助网络直接结合到了上层,认为这样domain的输出可以直接影响到最终的预测,有的场景认为作用在下层效果更好,比如poso给出的理由是,更下层特征更粗糙,没被加工过,更接近原始表达,所以作用在这个位置效果更好。
好像各自说的都有点道理,我在实践中感觉也是加在更下层,比如作用在expert,比作用在上层tower影响要更大一些。不过我感觉这可能更多和具体模型相关,因为我所添加的场景中expert层的参数量多出上层tower几个量级,效果更好我觉得和影响到的参数量有关。同样的作用方式,如果是个上下层参数差不多的场景,从经验来说我认为作用在上层影响会更直接一些,反之作用在下层效果好些。
同理作为参数量最大的特征emb,如果也能进行个性化调整,相信一样是会产生效果,比如前面介绍的id冷启动,其实也是一种emb的参数个性化调节。https://blog.csdn.net/qjzcy/article/details/129093841?spm=1001.2014.3001.5501
二,作用方式
独立参数,效果最好,但是如果落入其中样本不够,也容易带来负迁移。所以大多数优化都提供了个性化调整都方案。虽然调整的方式有些差异,不过本质上都是针对不同domian对一套公共的参数分布做针对性变化调整(scale&shift)。值得一提点是poso的参数优化方案,它通过简化它把参数分布的调整用向量点乘的方式完成了,这使得参数的调整就非常简便,可以比较快速的实现和部署到模型各个地方。如下公式

图九
三,划分属性的差异,
用户群,domian,消费,预估目标,等等。这里我们经常可以看到样本进行等频或者等距划分,个人理解等距是一个物理含义比较明确的划分,也比较清晰。等频是为了不同桶里样本量尽量相当,不然因为有共享等底层,一些同样本量过少,在梯度回传的时候容易劣势,导致负迁移的产生。所以一般都等距划分后再接个等频。
四,一点思考
综上,可以看到虽然优化等版本很多,但是本质就是不同domian的参数的个性化,并且domian的获取都严重依赖先验的知识,在这个domian下模型是否存在问题,是不是最大的问题,或者模型是不是还有其它问题,并没有很好的回答。所以我们在想是不是可以进一步做个大统一的模型,让模型自动识别出哪些属性或者属性组合分布存在着严重不一致,然后通过大统一模型来解决这个问题呢?先做实验吧,后续有结果再补充
。