
Netty性能利器 详解时间轮HashedWheelTimer
文章目录
- 1. 定时任务
- 2. JDK的定时任务工具
- 2.1 Timer
- 2.2 ScheduledThreadPoolExecutor
- 3. 时间轮原理分析
- 4. Netty定时任务调度 HashedWheelTimer
- 4.1 接口定义
- 4.2 快速上手
- 4.3 源码剖析
- 4.3.1 时间轮核心属性
- 4.3.2 时间轮创建过程
- 4.3.3 时间轮添加任务
- 4.3.4 时间轮执行任务
- 4.3.5 停止时间轮
- 4.4 Netty 时间轮局限性
- 5 时间轮进阶应用
Netty 中有很多场景依赖定时任务实现,比较典型的有客户端连接的超时控制、通信双方连接的心跳检测等场景。JDK实现的定时任务难以满足Netty的性能要求,为了实现高性能的定时任务调度,Netty 引入了时间轮算法驱动定时任务的执行。本文将简单回顾JDK定时任务的实现,剖析时间轮原理,以及Netty是如何实现时间轮算法。
本文参考Netty源码版本为 netty-4.1.56.Final
1. 定时任务
定时任务就是,需要在某一时刻或一段时间后自动执行,或周期执行的任务。
使用场景
定时任务使用场景非常广泛,例如生成月统计报表、财务对账、会员积分结算、邮件推送等。
表现形式
按固定周期定时执行、延迟一定时间后执行、指定某个时刻执行。
设计思路
定时器的本质是设计一种数据结构,能够存储和调度任务集合,而且 deadline 越近的任务拥有更高的优先级,然后通过轮询的方式,每隔一个时间片去检查任务是否到期。
所以定时器的内部结构一般需要一个任务队列和一个异步轮询线程,并且能够提供三种基本操作:
- Schedule 新增任务至任务集合;
- Cancel 取消某个任务;
- Run 执行到期的任务。
JDK提供了三种实现定时任务的工具,Timer、DelayedQueue 和 ScheduledThreadPoolExecutor。
2. JDK的定时任务工具
2.1 Timer
Timer是JDK 1.3开始就实现的定时任务,它可以实现固定周期的任务,以及延迟任务。Timer 会起动一个异步线程去执行到期的任务,任务可以只被调度执行一次,也可以周期性执行。
TImer的使用也比较简单:
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {// ...}// 2s 后调度一个周期为 1s 的定时任务
}, 5000, 1000);
再看一下Timer的内部结构:
public class Timer {private final TaskQueue queue = new TaskQueue();private final TimerThread thread = new TimerThread(queue);public Timer(String name) {thread.setName(name);thread.start();}
}
与前面的说的设计思路是一样的,维护一个任务队列TaskQueue和轮询线程TimerThread。
这里TaskQueue的实现是一个最小堆,deadline 最近的任务位于堆顶端。所以使用小根堆的数据结构,Run 操作时间复杂度 O(1),新增 Schedule 和取消 Cancel 操作的时间复杂度都是 O(logn)。
TimerThread 会定时轮询 TaskQueue 中的任务,如果堆顶的任务的 deadline 已到,那么执行任务。如果是单次任务,执行完则删除任务,如果是周期性任务,执行完放回。
Timer 其实目前并不推荐用户使用,它存在不少设计缺陷。
- Timer 是单线程模式。如果某个 TimerTask 执行时间很久,会影响其他任务的调度。
- Timer 的任务调度是基于系统绝对时间的,如果系统时间不正确,可能会出现问题。
- TimerTask 如果执行出现异常,Timer 并不会捕获,会导致线程终止,其他任务永远不会执行。
2.2 ScheduledThreadPoolExecutor
JDK 1.5开始,提供定时任务线程池 ScheduledThreadPoolExecutor,具有更加丰富的定时任务的特性,
简单使用:
public static void main(String[] args) {// 实际工作中不推荐直接使用Executors创建线程池,应当自定义线程池参数ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);// 5s 延迟后开始执行任务,每 1s 重复执行一次executor.scheduleAtFixedRate(() -> System.out.println("Hello World"), 5000, 1000, TimeUnit.MILLISECONDS); }
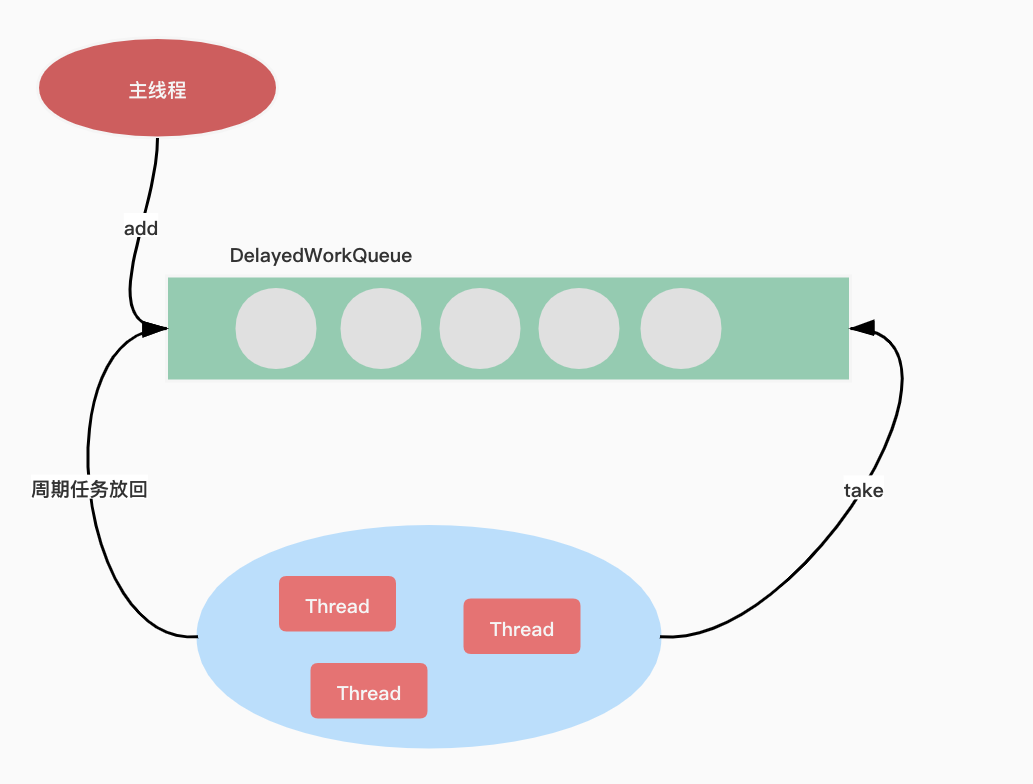
ScheduledThreadPoolExecutor 继承于 ThreadPoolExecutor,属于线程池的一种。线程池有两个重要的角色,分别是任务和阻塞队列。ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上,重新设计了任务 ScheduledFutureTask 和阻塞队列 DelayedWorkQueue。ScheduledFutureTask 继承于 FutureTask,并重写了 run() 方法,使其具备周期执行任务的能力。DelayedWorkQueue 内部是优先级队列,deadline 最近的任务在队列头部。线程池执行完周期性任务放回队列。
ScheduledThreadPoolExecutor结构如图:
除了以上两种定时任务,jdk中的DelayedQueue也可以用来实现定时任务,设计思想也是一样,不过DelayQueue 只实现了任务管理的功能,需要与异步线程配合使用,并且任务需要实现Delayed的接口,该接口定义两个方法,compareTo() 方法进行优先级排序。getDelay() 方法用于计算消息延迟的剩余时间。
上述三种定时器都离不开任务、任务管理、任务调度三个角色。三种定时器新增和取消任务的时间复杂度都是 O(logn),面对海量任务插入和删除的场景,这三种定时器都会遇到比较严重的性能瓶颈。
因此,对于Netty这种有海量任务插入和删除,性能要求较高的场景,我们一般都会采用时间轮算法实现定时任务调度。那么时间轮又是如何解决海量任务插入和删除的呢?
3. 时间轮原理分析
时间轮算法的设计思想来源于钟表。如下图所示,时间轮可以理解为一种环形结构,像钟表一样被分为多个 slot 槽位。每个 slot 代表一个时间段,每个 slot 中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。时间轮通过一个时针随着时间一个个 slot 转动,并执行 slot 中的所有到期任务。
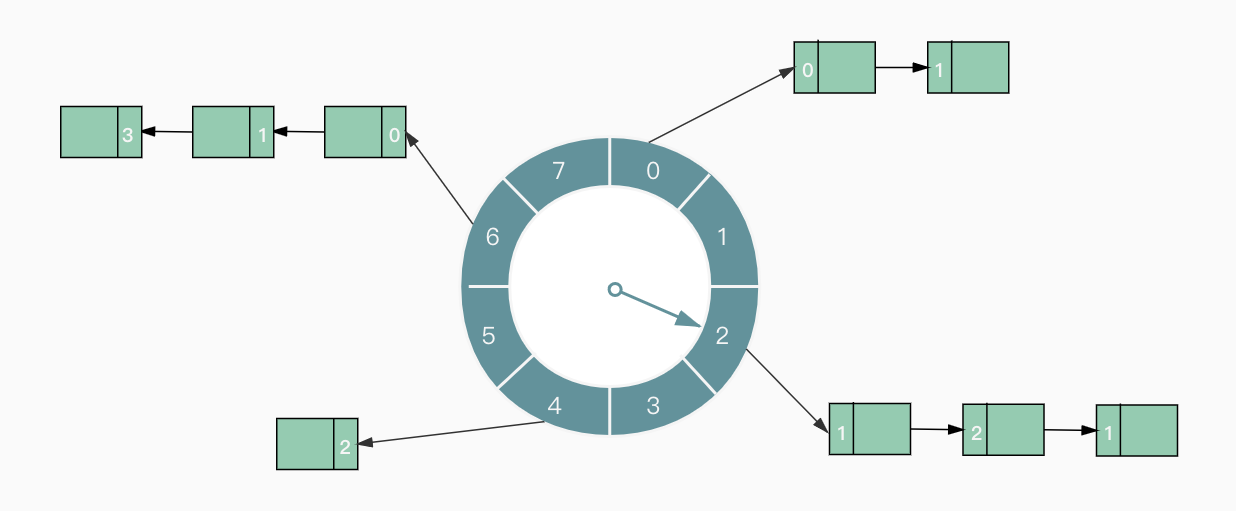
添加任务时,任务设置的延迟时间对slot个数取模,将任务放到对应的slot的链表里。同时记录商,上图中元素中的数字就是商,代表时针需要走过的圈数 round。当时针到达对应slot,只会执行该slot的链表里round为0的任务,不为0的任务统统round-1。
以上图举例说明,假设时间轮的slot个数为8,每个slot代表1s,当前时针指向2,现在需要添加一个18s后执行的任务,则需添加到的slot对应号码为(2 + 18%8 = 4),round=18/8=2,当时针第一次到达slot4,也就是2s后,链表中只有一个round为2的任务,则只将改任务round-1,变成1,当指针转了两圈再次来到slot4,此时该任务round已为0,则执行任务,如果是单次任务,则执行完删除,如果是周期性任务,则重新取模和计算round放进对应的slot。
根据以上描述的时间轮原理,可以看出以下几点:
- 时间轮将任务根据执行时间放在多个链表里,在任务元素里维护round,不必考虑插入链表的位置,添加任务时间复杂度O(1),但是使用了更多的空间,属于空间换时间思路。
- 任务执行时间点的准确性取决于slot代表的时间粒度。
- 时间轮时针转动和处理任务是同一个线程,任务太多或太耗时,同时slot时间粒度太小,可能造成任务阻塞。
时间轮定时器最大的优势就是,任务的新增和取消都是 O(1) 时间复杂度,非常适合Netty这种有海量小型任务新增和删除的业务场景。下面就分析一下Netty是如何实现时间轮的。
4. Netty定时任务调度 HashedWheelTimer
4.1 接口定义
要研究HashedWheelTimer ,先从他的上层接口切入,HashedWheelTimer 实现了接口 io.netty.util.Timer:
public interface Timer {Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);Set stop();
}
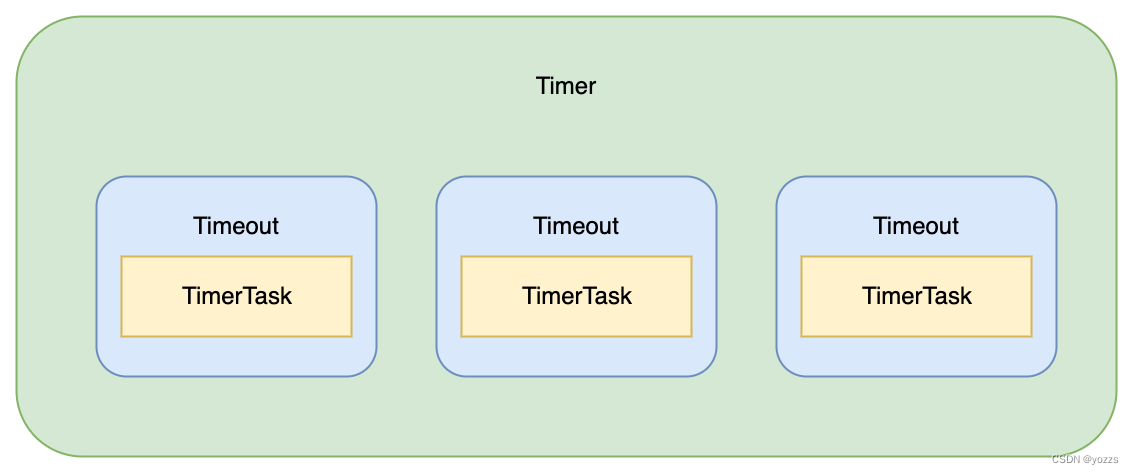
Timer 接口提供了两个方法,分别是创建任务 newTimeout() 和停止所有未执行任务 stop()。从方法的定义可以看出,Timer 可以认为是上层的时间轮调度器,通过 newTimeout() 方法可以提交一个任务 TimerTask,并返回一个 Timeout。
TimerTask 和 Timeout 是两个接口类:
public interface TimerTask {void run(Timeout timeout) throws Exception;
}public interface Timeout {Timer timer();TimerTask task();boolean isExpired();boolean isCancelled();boolean cancel();
}
Timeout 持有 Timer 和 TimerTask 的引用,而且通过 Timeout 接口可以执行取消任务的操作。这三个接口界限划分感觉不是很友好,不太好理清关系,Timer、Timeout 和 TimerTask 之间的关系如下图所示:
4.2 快速上手
public class TestMain {public static void main(String[] args) {Timer timer = new HashedWheelTimer();Timeout timeout1 = timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {System.out.println("timeout1: " + new Date());}}, 10, TimeUnit.SECONDS);if (!timeout1.isExpired()) {timeout1.cancel();}timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws InterruptedException {System.out.println("timeout2: " + new Date());Thread.sleep(5000);}}, 1, TimeUnit.SECONDS);timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {System.out.println("timeout3: " + new Date());}}, 3, TimeUnit.SECONDS);}
}
输出:
timeout2: Tue Mar 21 11:43:00 CST 2022
timeout3: Tue Mar 21 11:43:05 CST 2022
这个 demo 展示了HashedWheelTimer的简单使用,task1被取消,没有执行,task3原本应该延迟3秒输出,却在 task2输出5s 之后再输出,由此可见,时间轮中的任务执行是串行的,当一个任务执行的时间过长,会影响后续任务的调度和执行,很可能产生任务堆积的情况。
对 HashedWheelTimer 的基本使用方法有了初步了解后,下面深入研究 HashedWheelTimer 的实现原理。
4.3 源码剖析
4.3.1 时间轮核心属性
首先从HashedWheelTimer构造函数看看时间轮结构的实现:
public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,long maxPendingTimeouts) {// 省略其他代码// 创建时间轮的环形数组结构wheel = createWheel(ticksPerWheel); // 用于快速取模的掩码mask = wheel.length - 1;// 转换成纳秒处理long duration = unit.toNanos(tickDuration); // 省略其他代码// 创建工作线程workerThread = threadFactory.newThread(worker); // 是否开启内存泄漏检测leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null; // 最大允许等待任务数,HashedWheelTimer 中任务超出该阈值时会抛出异常this.maxPendingTimeouts = maxPendingTimeouts; // 如果 HashedWheelTimer 的实例数超过 64,会打印错误日志if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {reportTooManyInstances();}
}HashedWheelTimer 的构造函数清晰地列举出了几个核心属性:
- threadFactory,线程池,但是只创建了一个线程;
- tickDuration,时针每次 tick 的时间,相当于时针间隔多久走到下一个 slot;
- unit,表示 tickDuration 的时间单位;
- ticksPerWheel,时间轮上一共有多少个 slot,默认 512 个。分配的 slot 越多,占用的内存空间就越大;
- leakDetection,是否开启内存泄漏检测;
- maxPendingTimeouts,最大允许等待任务数。
4.3.2 时间轮创建过程
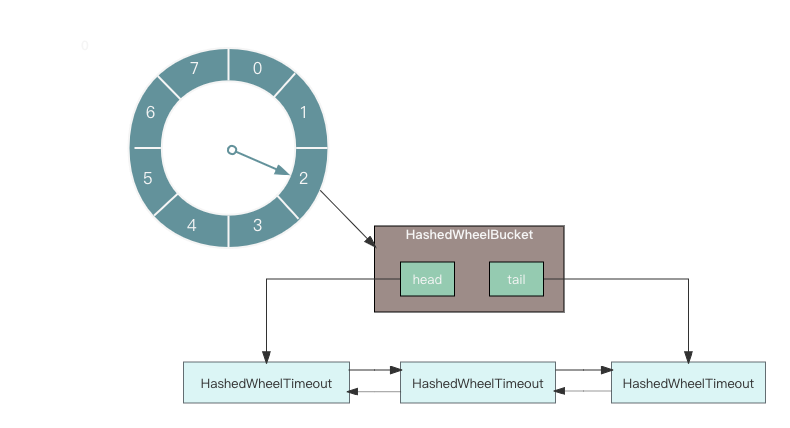
private static HashedWheelBucket[] createWheel(int ticksPerWheel) {// 省略其他代码ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];for (int i = 0; i < wheel.length; i ++) {wheel[i] = new HashedWheelBucket();}return wheel;
}private static int normalizeTicksPerWheel(int ticksPerWheel) {int normalizedTicksPerWheel = 1;while (normalizedTicksPerWheel < ticksPerWheel) {normalizedTicksPerWheel <<= 1;}return normalizedTicksPerWheel;
}private static final class HashedWheelBucket {// 双向链表结构private HashedWheelTimeout head;private HashedWheelTimeout tail;// 省略其他代码
}private static final class HashedWheelTimeout implements Timeout {private final HashedWheelTimer timer;private final TimerTask task;private final long deadline;private volatile int state = ST_INIT;long remainingRounds; HashedWheelTimeout next;HashedWheelTimeout prev;HashedWheelBucket bucket;
}时间轮的创建就是为了创建 HashedWheelBucket 数组,每个 HashedWheelBucket 表示时间轮中一个 slot。从 HashedWheelBucket 的结构定义可以看出,HashedWheelBucket 内部是一个双向链表结构,HashedWheelTimeout 代表一个定时任务。
因为时间轮需要使用 & 做取模运算,所以数组的长度需要是 2 的次幂。normalizeTicksPerWheel() 方法的作用就是找到不小于 ticksPerWheel 的最小 2 次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
private static int normalizeTicksPerWheel(int ticksPerWheel) {int n = ticksPerWheel - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}时间轮结构
4.3.3 时间轮添加任务
HashedWheelTimer 初始化完成后,通过 newTimeout()方法添加任务
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {// 省略其他代码long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {pendingTimeouts.decrementAndGet();throw new RejectedExecutionException("Number of pending timeouts ("+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "+ "timeouts (" + maxPendingTimeouts + ")");}// 1. CAS 判断,如果 worker 线程没有启动,需要启动start(); // 计算任务的 deadlinelong deadline = System.nanoTime() + unit.toNanos(delay) - startTime; if (delay > 0 && deadline < 0) {deadline = Long.MAX_VALUE;}// 2. 创建定时任务HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline); // 3. 添加任务到 Mpsc Queuetimeouts.add(timeout); return timeout;
}private final Queue timeouts = PlatformDependent.newMpscQueue();
newTimeout() 方法主要做了三件事,分别为
- 启动工作线程:通过CAS 判断工作线程是否启动,没有启动则CAS启动
- 创建定时任务:根据用户传入的延迟时间,计算出 deadline,从而确定任务放在哪个 slot 里
- 把任务添加到 Mpsc Queue:Mpsc Queue是一个多生产者单消费者高性能无锁队列,能保证添加任务的线程安全性,并保证高性能。
HashedWheelTimer 的工作线程采用了懒启动的方式,不需要用户显示调用。这样做的好处是在时间轮中没有任务时,可以避免工作线程空转而造成性能损耗。
那么什么时候任务才会被加入时间轮并执行呢?
4.3.4 时间轮执行任务
时间轮任务执行和调度由工作线程完成,工作线程 Worker 是时间轮的核心引擎,随着时针的转动,到期任务的处理都由 Worker 处理完成。
private final class Worker implements Runnable {private final Set unprocessedTimeouts = new HashSet();private long tick;@Overridepublic void run() {startTime = System.nanoTime();if (startTime == 0) {// startTime为0标识工作线程未启动startTime = 1;}// 通知其他等待初始化的线程startTimeInitialized.countDown();do {// 1. 计算下次 tick 的时间, 然后sleep 到下次 tickfinal long deadline = waitForNextTick();// 可能因为溢出或者线程中断,造成 deadline <= 0if (deadline > 0) {// 2. 获取当前 tick 在 HashedWheelBucket 数组中对应的下标int idx = (int) (tick & mask);// 3. 移除被取消的任务processCancelledTasks();HashedWheelBucket bucket = wheel[idx];// 4. 从 Mpsc Queue 中取出任务加入对应的 slot 中transferTimeoutsToBuckets();// 5. 执行到期的任务bucket.expireTimeouts(deadline);tick++;}} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);// 时间轮退出后,取出 slot 中未执行且未被取消的任务,并加入未处理任务列表,以便 stop() 方法返回for (HashedWheelBucket bucket: wheel) {bucket.clearTimeouts(unprocessedTimeouts);}// 将还没来得及添加到 slot 中的任务取出,如果任务未取消则加入未处理任务列表,以便 stop() 方法返回for (;;) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (!timeout.isCancelled()) {unprocessedTimeouts.add(timeout);}}processCancelledTasks();}}
工作线程 Worker 的核心执行流程是代码中的 do-while 循环,只要 Worker 处于 STARTED 状态,就会执行 do-while 循环,我们把该过程拆分成为以下几个步骤,逐一分析:
- 通过 waitForNextTick() 方法计算出时针到下一次 tick 的时间间隔,然后 sleep 到下一次 tick。
- 通过位运算获取当前 tick 在 HashedWheelBucket 数组中对应的下标
- 移除被取消的任务。
- 从 Mpsc Queue 中取出任务加入对应的 HashedWheelBucket 中。
- 执行当前 HashedWheelBucket 中的到期任务。
第一步 : 根据 tickDuration 可以推算出下一次 tick 的 deadline,deadline 减去当前时间就可以得到需要 sleep 的等待时间。所以 tickDuration 的值越小,时间的精准度也就越高,同时 Worker 的繁忙程度越高。如果 tickDuration 设置过小,为了防止系统会频繁地 sleep 再唤醒,会保证 Worker 至少 sleep 的时间为 1ms 以上。
第二步 :Worker 从 sleep 状态唤醒后,接下来会执行第二步流程,通过按位与的操作计算出当前 tick 在 HashedWheelBucket 数组中对应的下标。按位与比普通的取模运算效率要快很多,前提是时间轮中的数组长度是 2 的次幂,掩码 mask 为 2 的次幂减 1,这样才能达到与取模一样的效果。
第三步 : 接下来 Worker 会调用 processCancelledTasks() 方法处理被取消的任务,所有取消的任务都会加入 cancelledTimeouts 队列中,Worker 会从队列中取出任务,然后将其从对应的 HashedWheelBucket 中删除,删除操作为基本的链表操作。
第四步 :transferTimeoutsToBuckets() 方法,从 Mpsc Queue中取出任务放入 slot
private void transferTimeoutsToBuckets() {// 每次时针 tick 最多只处理 100000 个任务,以防阻塞 Worker 线程for (int i = 0; i < 100000; i++) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}// 如果任务被取消,跳过if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {continue;}// 计算任务需要经过多少个 ticklong calculated = timeout.deadline / tickDuration; // 计算任务需要在时间轮中经历的圈数 remainingRoundstimeout.remainingRounds = (calculated - tick) / wheel.length;// 如果任务在 timeouts 队列里已经过了执行时间, 那么会加入当前 HashedWheelBucket 中 final long ticks = Math.max(calculated, tick); int stopIndex = (int) (ticks & mask);HashedWheelBucket bucket = wheel[stopIndex];bucket.addTimeout(timeout);}
}第五步 : 接下来就是执行当前 HashedWheelBucket 中的到期任务,跟进 HashedWheelBucket#expireTimeouts() 方法的源码:
public void expireTimeouts(long deadline) {HashedWheelTimeout timeout = head;while (timeout != null) {HashedWheelTimeout next = timeout.next;if (timeout.remainingRounds <= 0) {next = remove(timeout);if (timeout.deadline <= deadline) {// 执行任务timeout.expire(); } else {throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));}} else if (timeout.isCancelled()) {next = remove(timeout);} else {// 未到执行时间,remainingRounds 圈数减 1timeout.remainingRounds --; }timeout = next;}
}
如果 remainingRounds <=0,则调用 expire() 方法执行任务,timeout.expire() 内部就是调用了 TimerTask 的 run() 方法。如果任务已经被取消,直接从链表中移除。否则表示任务的执行时间还没到,remainingRounds 减 1,等待下一圈即可。
最后,当工作线程的线程状态被改变,工作线程 Worker 的核心逻辑 do-while 循环结束,Worker 还会执行一些后置的收尾工作。Worker 会从每个 HashedWheelBucket 取出未执行且未取消的任务,以及还来得及添加到 HashedWheelBucket 中的任务,然后加入未处理任务列表,以便 stop() 方法统一处理。
4.3.5 停止时间轮
Timer 接口两个方法,newTimeout() 上文已经分析完了,接下来以 stop() 方法为入口,看下时间轮停止都做了哪些工作。
@Overridepublic Set stop() {// Worker 线程无法停止时间轮,防止用户的定时任务有恶意操作if (Thread.currentThread() == workerThread) {throw new IllegalStateException(HashedWheelTimer.class.getSimpleName() +".stop() cannot be called from " +TimerTask.class.getSimpleName());}// 尝试通过 CAS 操作将工作线程的状态更新为 SHUTDOWN 状态if (!WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_STARTED, WORKER_STATE_SHUTDOWN)) {if (WORKER_STATE_UPDATER.getAndSet(this, WORKER_STATE_SHUTDOWN) != WORKER_STATE_SHUTDOWN) {INSTANCE_COUNTER.decrementAndGet();if (leak != null) {boolean closed = leak.close(this);assert closed;}return Collections.emptySet();}try {boolean interrupted = false;while (workerThread.isAlive()) {// 中断 Worker 线程workerThread.interrupt(); try {workerThread.join(100);} catch (InterruptedException ignored) {interrupted = true;}}if (interrupted) {Thread.currentThread().interrupt();}} finally {INSTANCE_COUNTER.decrementAndGet();if (leak != null) {boolean closed = leak.close(this);assert closed;}}// 返回未处理任务的列表return worker.unprocessedTimeouts();
} 如果当前线程是 Worker 线程,它是不能发起停止时间轮的操作的,是为了防止有定时任务发起停止时间轮的恶意操作。
停止时间轮主要做了三件事:
- 首先尝试通过 CAS 操作将工作线程的状态更新为 SHUTDOWN 状态,
- 然后中断工作线程 Worker,
- 最后将未处理的任务列表返回给上层。
至此,HashedWheelTimer 的实现原理我们已经分析完了。HashedWheelTimer 的几个核心成员:
- HashedWheelTimeout,任务的封装类,包含任务的到期时间 deadline、需要经历的圈数 remainingRounds 等属性。
- HashedWheelBucket,相当于时间轮的每个 slot,内部采用双向链表保存了当前需要执行的 HashedWheelTimeout 列表。
- Worker,HashedWheelTimer 的核心工作引擎,负责处理定时任务。
4.4 Netty 时间轮局限性
HashedWheelTimer 并不是十全十美的,使用的时候需要清楚它存在的问题:
- 如果长时间没有到期任务,那么会存在时间轮空推进的现象。
- 只适用于处理耗时较短的任务,由于 Worker 是单线程的,如果一个任务执行的时间过长,会造成 Worker 线程阻塞。
- 相比传统定时器的实现方式,内存占用较大。
5 时间轮进阶应用
Netty 实现的时间轮在某些场景还是有性能浪费的,它通过固定的时间间隔 tickDuration 进行推动,如果长时间没有到期任务,那么会存在时间轮空推进的现象,从而造成一定的性能损耗。此外,如果任务的到期时间跨度很大,例如 A 任务 1s 后执行,B 任务 6 小时之后执行,也会造成空推进的问题。
Kafka 的时间轮结构跟 Netty 相似,针对空推进问题,kafka 做了一些优化。
- 使用JDK 的 DelayQueue 代替 do-while 循环进行调度,当某一个 slot 没有到期任务可执行时,会阻塞等待,解决空推进问题。
- 针对到期时间跨度大的问题,Kafka 引入了层级时间轮,当任务的 deadline 超出当前所在层的时间轮表示范围时,就会尝试将任务添加到上一层时间轮中,跟钟表的时针、分针、秒针的转动规则是同一个道理。