
236页10万字数据中台建设方案2022版
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除。
部分资料内容:
1.1.1.1. 数据联邦
虚拟数据库(Virtual Database–VDB) 是将一个或多个物理数据源组合起来以提供更简单的数据集成解决方案,它提供了包含组件的容器,这些组件用来集成不同数据源的数据,并通过一致的 API 来访问它们,这些物理数据源包括: JDBC数据源、CSV 文本文件、数据表,甚至可以是 Web services。
这种技术被称为是“数据联邦” -Data federation。数据联邦技术提供了一种为数据提供抽象的数据接口的能力。这些多个数据源组成的虚拟视图可以使数据消费者(应用)不需要知道数据的物理位置、数据结构和保存方式。
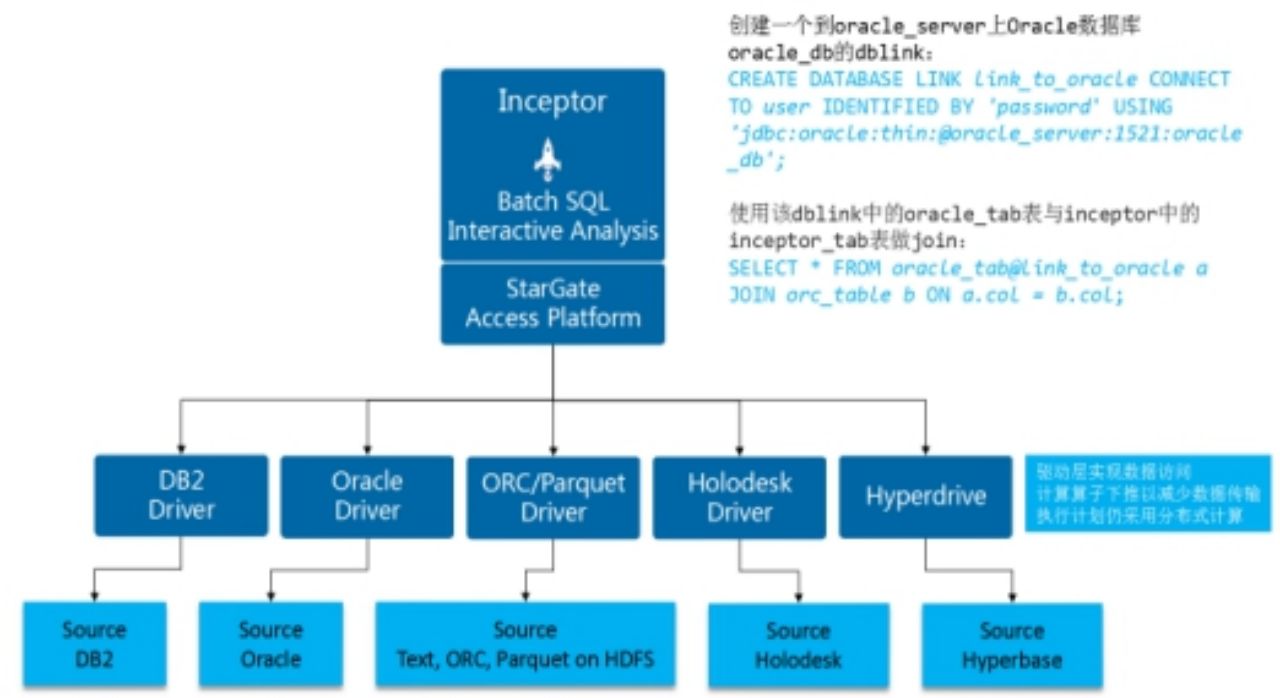
对于采集到的数据因为存放位置不同可能引起的“数据孤岛”问题,Transwarp Inceptor中引入了数据源连接器Stargate,提供数据联邦功能。Stargate是连接执行引擎和各种数据源的连接器,可以将多种不同数据源的数据接入引擎做实时的统计分析,而无需事先将数据导入HDFS,从而更加方便用户的业务构建多样化需求。
Inceptor通过Stargate以及各个存储引擎/格式已经实现的驱动Driver,支持接入分布式内存列式存储Holodesk、分布式搜索引擎Search、分布式NoSQL数据库Hyperbase、列式存储ORC格式、Textfile存储格式等。
此外,对于关系型数据库Stargate兼容Oracle DB-Link规范,通过创建database link来预先建立和其它数据源的连接池,然后就是在SQL中通过dblink的方式在Inceptor中访问该数据源的数据。在执行计划开始以后,Stargate通过预先建立连接从其它数据源中抽取需要的数据,输入执行引擎层参与SQL计算。在计算完成后,释放相关的数据库连接以及对应的资源。
在查询计算完成之后,Startgate也支持通过SQL将数据在各种存储引擎与格式直接进行导入导出变换,可以将计算的结果写回指定的数据存储中,包括HDFS、Search、Holodesk、Hyperbase(K-V存储)、关系型数据库等。
1.1.1.2. 数据总线
基于高吞吐、高可靠的分布式消息队列的Kafka集群能够实现数据订阅和发布功能。在业务数据源与数据处理引擎中间实现了一个隐含的、基于数据的接口层。实现业务系统与大数据平台的解耦。数据总线模块还具备数据缓冲、数据冗余、可扩展性好等特性。使用Kafka作为消息队列,将数据生产者与数据消费者解耦合,适用于一个数据源需要多个订阅者、需要数据源与消费者之间需要异步通信的场景。可以用作数据缓冲队列,作为流处理的数据源。Transwarp Stream作为Kafka的消费者,使用StreamSQL对数据进行处理。在万兆网络,使用双副本的条件下,对于高效模式单台数据总线服务器支持的业务数据加载速度在300MB/s及以上,吞吐能力可以随集群规模线性扩展。对于可靠模式支持的业务数据单节点加载速度25M/s及以上,可以线性扩展至网络传输的极限。高效模式下数据丢失率在万分之一以内。可靠模式下加载数据要求与输入数据一致。单集群支持的数据总线服务器总数随集群规模扩展而增加,支持100节点以上的集群规模。数据从发布到订阅时延在1秒以内。
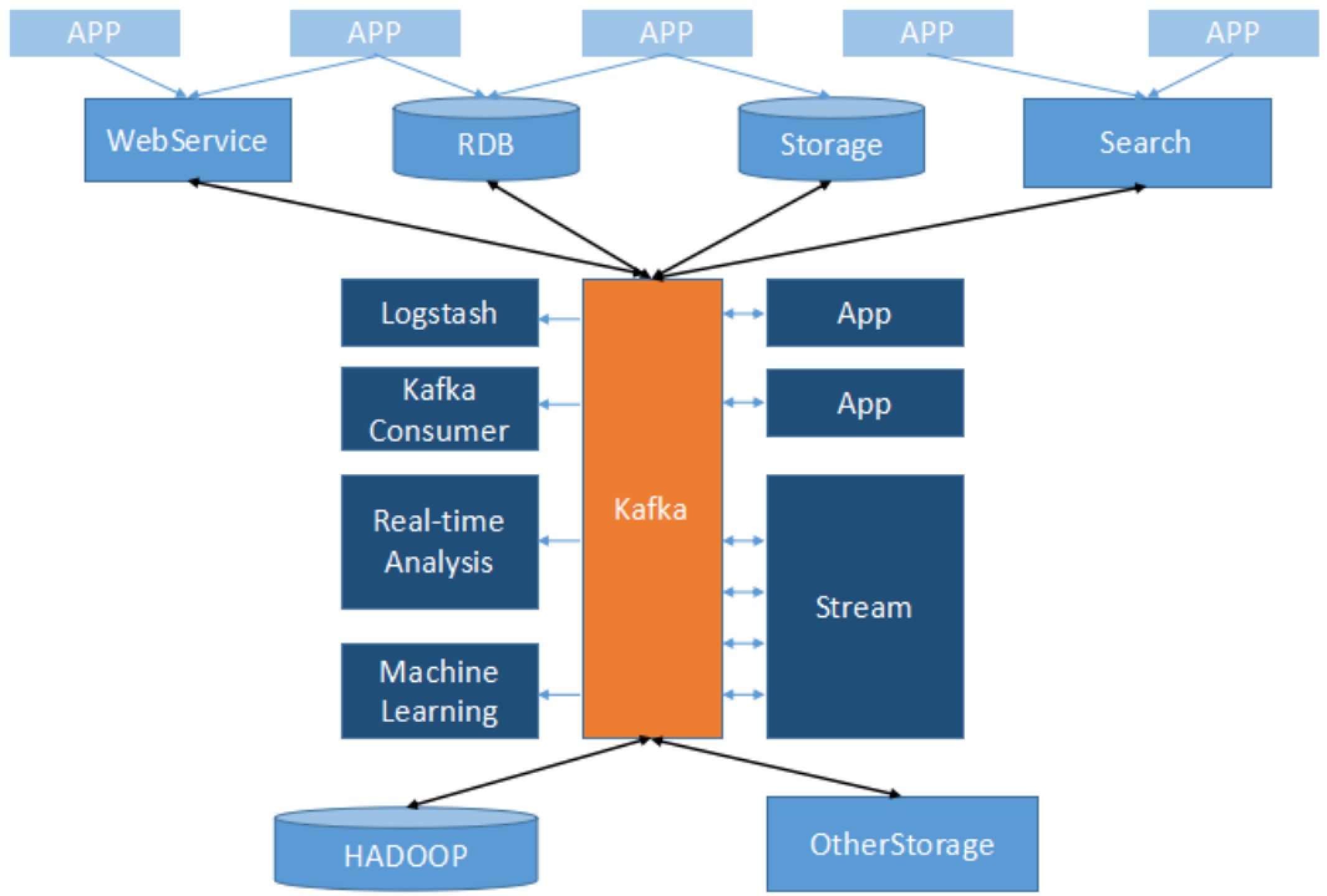
Kafka数据总线支持数据订阅和发布功能,可以通过定义消息总线发布端、订阅端、消息队列、数据格式等相关配置来发布数据总线并自动维护总线消息队列,自动对总线消息进行全流程监控。数据由数据客户端加载数据库中数据、由WebService业务系统的访问请求或者外部检索工具发出的请求消息,Kafka中支持缓存和传输结构化、半结构以及非结构化的各类数据。数据源包括:数据加载客户端、流处理引擎、数据表存储、数据抽取工具或者其他自定义的Kafka Producer。订阅客户端包括:流处理引擎、数据表存储、K-V存储或者自定义的Kafka Consumer。Kafka中可以在Topic上进行业务标记或者在传输的消息中对业务类型等信息进行标记。
Kafka支持跨集群同步,可以实现两个数据总线集群间的数据镜像。Kafka中支持建立多份Topic数据副本可靠数据传输机制。在可靠数据传输模式下可以保证从生产者到消费者之间数据不会丢失。在高效传输模式下允许数据有一定量的丢失,丢失率在万分之一以下。Kafka将数据缓存在本地磁盘中,通过文件数据队列的相应机制支持数据断点续传。Kafka支持在线服务平滑扩展,并且吞吐能力与集群规模线性正相关,Kafka总线消息队列集群支持数百节点的规模,理论上集群规模并无上限。Kafka支持通过Guardian对用户进行权限管理,用户经过相应的授权后才可以访问相关数据主题。
在万兆网络,使用双副本的条件下,对于高效模式单台数据总线服务器支持的业务数据加载速度不低于300MB/s,可以线性扩展。对于可靠模式支持的业务数据加载速度不低于20MB/s,可以线性扩展。高效模式下数据允许有万分之一以内的丢失。可靠模式下加载数据要求与输入数据一致。单集群支持的数据总线服务器总数不少于100台。数据从输入到订阅者能够订阅到时延不高于1秒。
1.1.1.3. 数据服务
TDH平台非常重视与数据分析生态系统的整合以提高系统的可用性。
与现有成熟系统的无缝整合涉及了数据获取,数据分析以及数据可视化端。传统的关系型数据库的数据可以直接作为数据源接入到集群中参与计算分析,目前已经支持Oracle,DB2及MySQL等数据库。
1) 与主流ETL工具集成
支持DataStage、Kettle、Informatica等主流ETL工具、实时数据复制工具、批处理任务调度工具,并能兼容其嵌入函数。
2) 与主流可视化工具集成
支持多种可视化及报表生成工具,包括Tableau、SAP Business Objects、Oracle OBIEE、IBM Cognos、MicroStrategy MSTR、FineReport以及SAS等,使得基于大数据分析的商业决策更易被理解和接受,从而将大数据的潜在价值最大化。虽然有些工具也支持Apache Hadoop,但只有高性能的TDH才真正使得交互式地探索大数据成为现实。
3) 与主流元数据管理软件平台集成
支持主流元数据管理软件平台,包括数据质量管理、数据生命期管理。
4) 与其他开源数据挖掘与数据建模工具软件集成
支持其他开源数据挖掘与数据建模工具软件。
此外,数据分析挖掘层与R语言的整合,使得数据分析挖掘不仅仅能使用 TDH中提供的并行统计算法库以及并行机器学习算法库,同时带来了R的数千种统计挖掘算法,可以充分利用R语言中的绘图工具绘制专业的统计报表;数据可视化不仅可将最终分析结果展示给用户,还可以帮助数据分析师来进行数据探索来发现新问题并分析解决。
1.1.1. 数据管理层建设
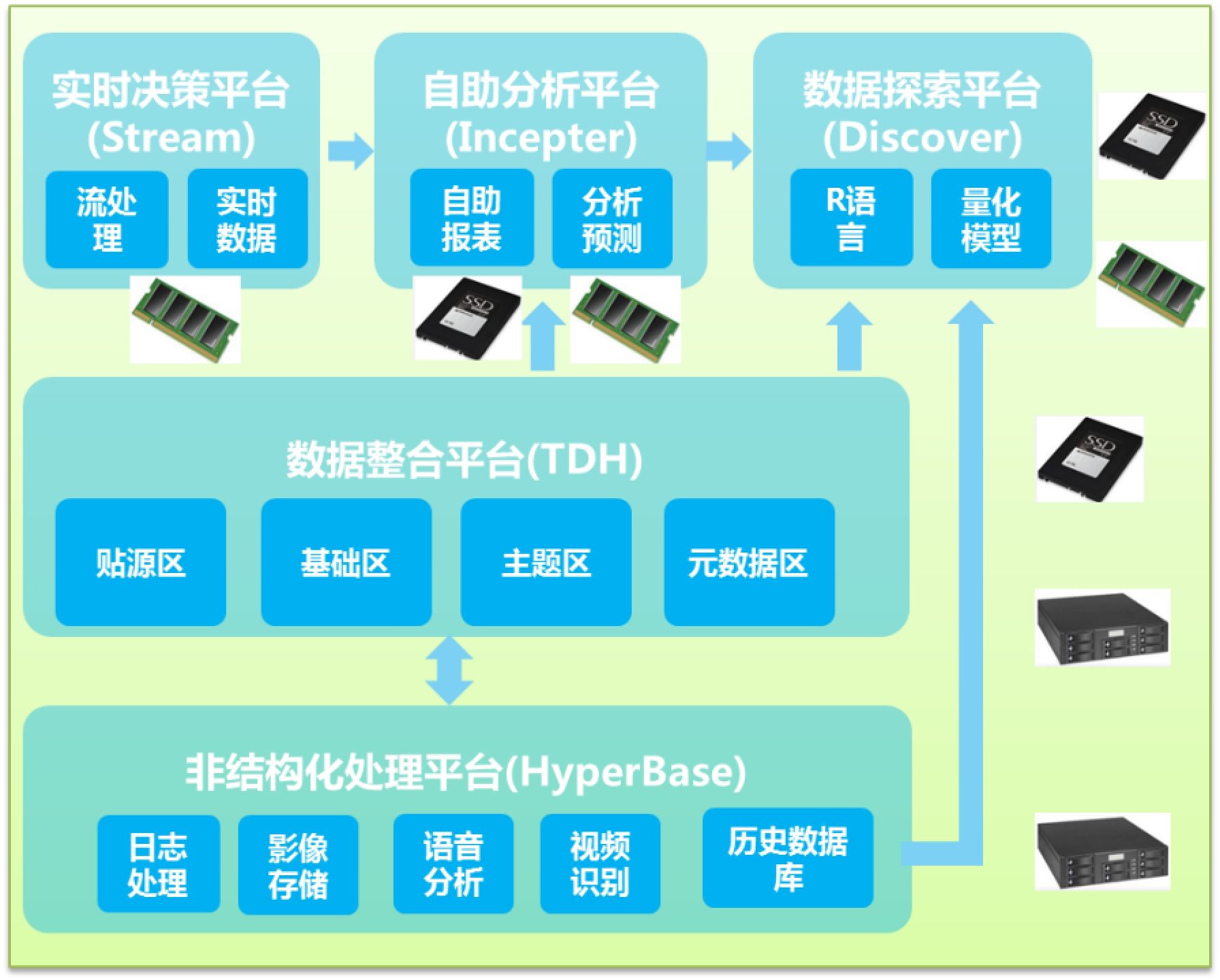
数据分区是为了访问数据时,速度更快的存储策略,针对不同的场景进行数据分区分布;
为了提升海量数据查询性能,提供表分区功能。Inceptor支持对表的单值分区和范围分区。 为一张表分区: 在物理上,将表中的数据按分区放在表目录下的对应子目录中,一个分区对应一个子目录;在逻辑上,分区表和未分区表没有区别。 分区在创建表时完成,也可以通过ALTER TABLE来添加或者删除。
关于分区的建议,分区的目的是减少扫描成本。所以单个分区的大小和总分区数目都应该控制在合理范围内。使用多层分区带来的直接问题是总分区个数过多,因为总分区个数是所有分区键对应分区个数的乘积。所以我们建议尽量减少使用多层分区对于时间、日期一类的值,使用单值分区会导致分区过多。推荐使用范围分区(RANGE PARTITION)。范围分区可以灵活控制分区的数量,并可根据数据本身的特点使得各个分区的大小也控制在合理范围内,从而使得应用性能得到保证。另外,有很多以往在Oracle系统上的应用都是采取的范围分区,对范围分区的支持也能使得原有应用程序的迁移更加简单。
如果是应用场景是批量处理场景,那么为了提高批处理的速度,一般在存储逻辑上,数据会放在HDFS上,基于Master/Slave架构提供高速批处理的性能。
如果是高速随机查询,那么为了提高随机查询性能,一般在存储逻辑上,会把数据放在Hyperbase上,基于HBase的架构,提供高速随机查询能力。
对于非重要冷数据,一般数据会存储在磁盘内,做多个备份,也可采用Erasure Code技术实现低成本存储,如果是热门数据,比如数据集市的精准内容,一般会改造成Holodesk的格式,存储在SSD或者内存当中;
1.1.1.1. 数据多温度管理
在大数据时代,对于海量数据应该考虑数据的分级存储方案以节约存储成本。通常,我们会把数据分为热数据,在线数据,近线数据和归档数据。不同的数据种类的应用和处理会有不同的需求。
对于热数据和在线数据,更多的需要考虑应用在使用数据时的高效性,Transwarp Inceptor用Holodesk的技术来加速热数据处理。对于近线数据,由于应用存取的需求相比热数据和在线数据大大减少,主要需要保证数据存储的可靠性,并考虑如何在保证可靠性的基础上能尽量减少副本以节约存储空间。
热数据
可以根据应用需求,将经常需要进行分析的热数据从HDFS或者Hyperbase中加载到Inceptor中的分布式内存数据列式存储Holodesk中。通过内存加速分析,在秒级别响应,对数据进行交互式探索挖掘。此外内存数据库还具备了通过R语言或者JAVA API对内存数据库中内容进行数据挖掘的能力。
在内存计算数据库的存储层,通过将二维数据表缓存入独立的分布式内存(或SSD)层,回避GC问题。并通过建立自定义高效列式存储结构,减少数据传输。星环的内存数据库不仅仅可以支持数据存储在内存中,同样支持内存加SSD的混合存储架构,使得内存数据库中数据不仅能存储在内存中也能存储在SSD中,并且性能不会受到太大的影响。很大程度上提升了内存数据库的容量以及整体的性价比。
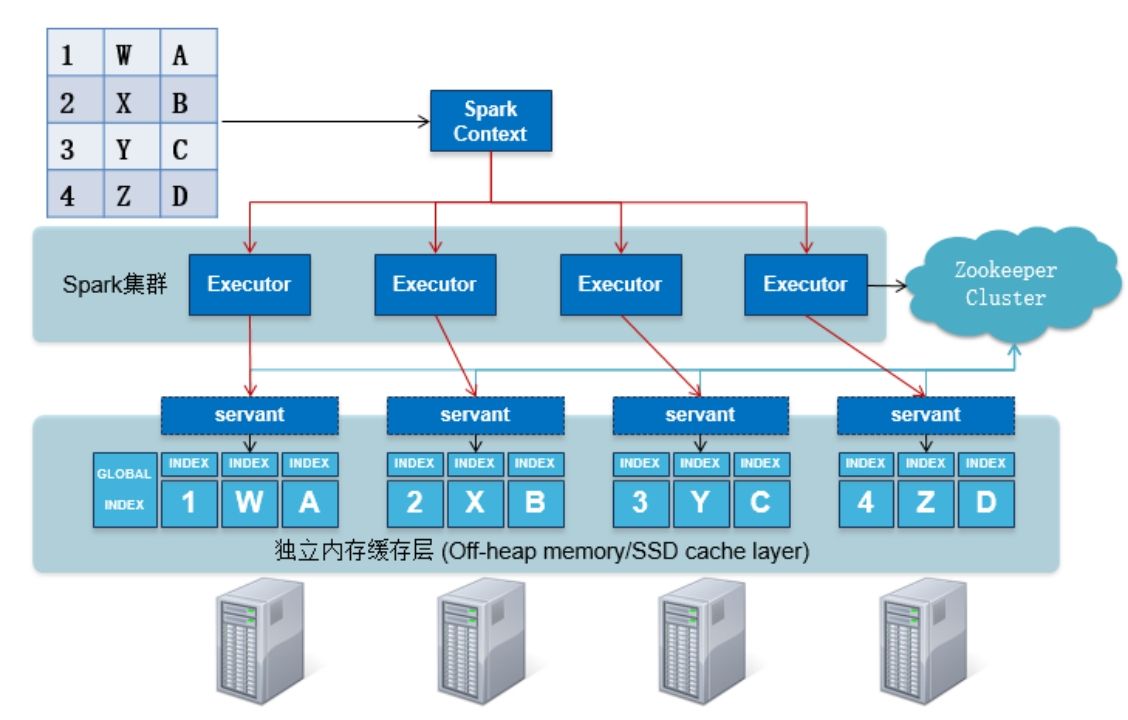
图 热数据存储
冷数据
冷数据可以使用Transwarp HDFS中Erasure Code功能减少副本。Erasure Code可配置策略,指定HDFS中目录,通过Raid Server监控,在指定生命周期后将指定目录下的文件降低其副本数为1,并由10个数据块生成4个冗余校验块的,将3倍存储开销降低到1.4倍,并且在数据可靠性方面,Erasure Code在14个数据块中可容忍任意4个块丢失,比3份冗余存储可容忍2份数据块丢失更可靠。冷数据可使用Erasure Code自动降低存储开销。
一个典型的应用场景:数据在导入HDFS后的一段时间内访问频繁,在一段时间后访问频率降低甚至正常状态下不访问。可以通过设置该数据的冷却时间,当这些数据到达冷却时间后,会自动触发降副本的进程。
1.1.1.1. 分布式数据仓库
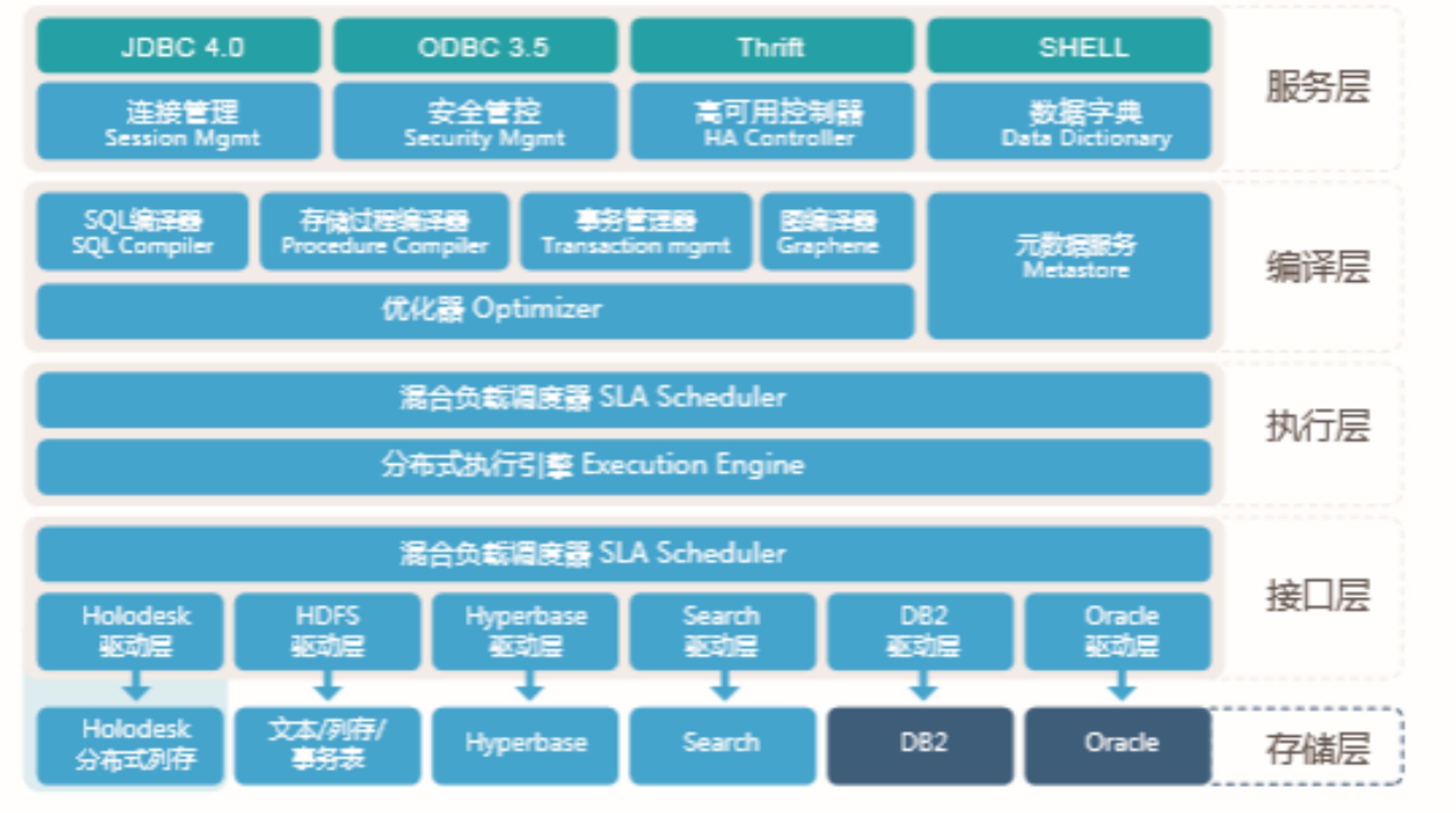
Transwarp Inceptor是一个企业级数据仓库,最下面是存储层接口层,Inceptor可将存储在分布式列存、文本/列存/事务表、Hyperbase、Search、DB2、Oracle中的数据,通过提供的对应驱动层,进入到执行层。在执行层中,Inceptor提供了混合负载调度器SLA Scheduler和分布式执行引擎。在编译层提供了各种编译器和优化器,以及元数据服务。最上层提供完整的交互访问接口和各类安全管控。
Spark是Map/Reduce计算模式的一个全新实现。Spark的创新之一是提出RDD(Resilient Distributed Dataset)的概念,所有的统计分析任务是由对RDD的若干基本操作组成。RDD可以被驻留在内存中,后续的任务可以直接读取内存中的数据,因此速度可以得到很大提升。Spark的创新之二是把一系列的分析任务编译成一个由RDD组成的有向无环图,根据数据之间的依赖性把相邻的任务合并,从而减少了大量的中间结果输出,极大减少了磁盘I/O,使得复杂数据分析任务更高效。从这个意义上来说,如果任务够复杂,迭代次数够多,Spark比Map/Reduce快100倍或1000倍都很容易。基于这两点创新,可在Spark基础上进行批处理、交互式分析、迭代式机器学习、流处理,因此Spark可以成为一个用途广泛的计算引擎,并在未来取代Map/Reduce的地位。
Inceptor可以分析存储在HDFS,HBase或者Holodesk分布式缓存中的数据,可以处理的数据量从GB到数十TB,即使数据源或者中间结果的大小远大于内存,也可高效处理。另外也通过改进Spark和YARN的组合,提高了Spark的可管理性。这些使得Inceptor成为目前真正适合企业生产环境7x24小时部署的Spark衍生产品。同时星环不仅仅是将Spark作为一个缺省计算引擎,也重写了SQL编译器,提供更加完整的SQL支持。
同时,星环通过改进Spark使之更好的与HBase融合。星环基于HBase的产品叫做Hyperbase,通过结合Inceptor,可以为HBase提供完整的SQL支持,包括批量SQL统计、OLAP分析以及高并发低延时的SQL查询能力,使得HBase的应用可以从简单的在线查询应用扩展到复杂分析和在线应用结合的混合应用中,大大拓展了HBase的应用范围。这两个产品的组合使得星环在市场上处于领先地位。
篇幅有限,无法完全展示,喜欢资料可转发+评论,私信了解更多信息。