
Java8新特性详解(二)Stream API使用
Stream API 有什么作用?
可以像SQL语句一样对集合、数组进行操作。
特点:
① Stream不会存储元素
② Stream 不会改变原对象
③ Stream 的 中间操作方法 要等到 终止操作方法 被调用时才会执行

一,Stream的创建方式
public class TestStream {public static void main(String[] args) {//1,通过集合的stream方法Stream stream1 = new ArrayList().stream();Stream stream2 = new HashSet().stream();//2.通过Arrays的stream方法Stream stream3 = Arrays.stream(new Integer[]{1, 2, 3});//3.通过Stream类本身提供的方法//3.1 of方法Stream stream4 = Stream.of("aaa", "bbb");//3.2 iterate方法,会像死循环一样不停的运行,所以用了limit(10)限制其只迭代10次//第一个参数是初始值,第二个参数是Function接口的子接口Stream stream5 = Stream.iterate(0, x -> x + 2);stream5.limit(10).forEach(System.out::println);//等同于下面的代码int i=0;int x = 0;while (true){if(i>=10){break;}x = x+2;System.out.println(x);i++;}//3.3 generate方法,参数是一个Supplier接口,会像死循环一样不停的运行,所以用了limit(10)限制其只迭代10次Stream stream6 = Stream.generate(()->Math.random());stream6.limit(10).forEach(System.out::println);}
} 二,中间操作
多个中间操作方法可以连起来使用,在调用终止操作方法前,中间操作不会执行,而在终止操作时一次性执行完成,这叫"惰性求值"
中间操作的方法包含:
方法 | 说明 |
filter(Predicate p) | 筛选,匹配符合规则的元素 |
distinct() | 筛选,通过hashcode 和 equals去除重复元素 |
limit(long maxSize) | 筛选,取不超过给定数量的元素 |
skip(long n) | 筛选,跳过前n个元素,若流中元素不足n个则返回空流 |
map(Function | 映射,输入一个T类型的元素,返回一个R类型的元素; 如果返回的类型是也是Stream类型,会直接把Stream放入原Stream中 |
mapToDouble(ToDoubleFunction | 映射,输入一个T类型的元素,返回一个Double类型的元素 |
mapToLong(ToLongFunction | 映射,输入一个T类型的元素,返回一个Long类型的元素 |
flatMap(Function | 映射,输入一个T类型的元素,返回一个R类型的元素; 如果返回的类型是也是Stream类型,会把Stream中的元素取出放入原Stream中; |
sorted() | 排序,按自然顺序排序,产生一个新流 |
sorted(Comparator comp) | 排序,按比较器排序,产生一个新流 |
如果只做中间操作,是不会产生任何执行的,比如:
//定义User类
public class User {private String name;private int age;public User(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {System.out.println("getAge 方法执行");return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +'}';}
}//测试类
public class Test1 {static List userList = Arrays.asList(new User("A",20),new User("B",25),new User("C",30));public static void main(String[] args) {//需求:获取age>20的userStream userStream = userList.stream().filter(user -> user.getAge() > 20);System.out.println("运行结束");}
} 运行后输出如下,并未输出 getAge方法内的内容:

所以中间操作需要与终止操作一起使用,例如使用终止操作forEach方法进行输出。
示例一: filter(Predicate p) 的使用
public static void main(String[] args) {//需求:获取age>20的useruserList.stream().filter(user -> user.getAge() > 20).forEach(System.out::println);System.out.println("运行结束");}运行结果如下:
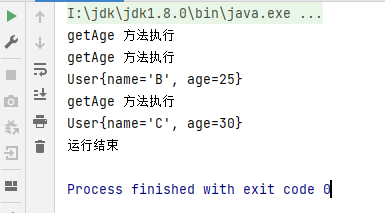
示例二: limit 的使用
public static void main(String[] args) {//需求:获取age>20的useruserList.stream().filter(user -> user.getAge() > 20).limit(1).forEach(System.out::println);System.out.println("运行结束");}输出结果如下:

可以看出一旦达到limit的个数,遍历就会结束,不会继续遍历剩下的元素。
示例三: skip的使用
public static void main(String[] args) {//需求:获取age>20的useruserList.stream().skip(2).forEach(System.out::println);System.out.println("运行结束");}输出结果如下:

示例四: distinct的使用
由于根据hashcode和equals去重复,所以User类需重写hashcode和equals方法才可去重
//定义User类,重写hashcode和equals方法
public class User {private String name;private int age;public User(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {System.out.println("getAge 方法执行");return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;return age == user.age && Objects.equals(name, user.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}//测试类
public class Test1 {//姓名C的User有3个重复的static List userList = Arrays.asList(new User("A",20),new User("B",25),new User("C",30),new User("C",30),new User("C",30));public static void main(String[] args) {//需求:获取age>20的useruserList.stream().distinct().forEach(System.out::println);System.out.println("运行结束");}
} 输出结果如下,只输出了一个姓名为C的用户,说明已经去重复:

示例五: map(Function
public static void main(String[] args) {//需求:将数组中的每个元素转大写//1.使用lambda表达式实现Function接口Arrays.stream(new String[]{"aaa","bbb","ccc"}).map(str->str.toUpperCase()).forEach(System.out::println);System.out.println("-----------------------");//2.使用lambda方法引用实现Function接口Arrays.stream(new String[]{"aaa","bbb","ccc"}).map(String::toUpperCase).forEach(System.out::println);
}如果不清楚lambad表达式和方法引用的写法,可以看前一篇文章
https://blog.csdn.net/weixin_43833851/article/details/129507783
运行结果如下:

示例六: flatMap(Function
与map的区别:
当map函数的返回值类型是也是Stream类型(Stream类型可以包含多个元素)时,
map会把 新Stream 直接 放入原Stream中,
flatMap会把 新Stream中的元素 一个个取出放入 原Stream中;
就好像是集合的add方法,flatMap就好像是集合的addAll方法,
,
示例:
public static void main(String[] args) {//需求:将数组中的每个元素拆分成单个字符输出//使用map函数,将toCharStream方法返回的 Stream作为一个元素 直接放到原Stream中Stream> outStream = Arrays.stream(new String[]{"aaa", "bbb"}).map(str -> toCharStream(str));//需要嵌套forEach才能完全遍历outStream.forEach(innerStream->innerStream.forEach(System.out::println));System.out.println("------------------------------");//使用flatmap函数,将toCharStream方法返回的 Stream 里面的元素取出,放入到原 stream中Stream flatStream = Arrays.stream(new String[]{"aaa", "bbb", "ccc"}).flatMap(str -> toCharStream(str));//不用嵌套forEachflatStream.forEach(System.out::println);}//将一个字符串转为 Stream,可以把Stream也看成是一种集合,里面存的是字符串拆成的字符
public static Stream toCharStream(String str){List list = new ArrayList<>();for (Character ch :str.toCharArray()){list.add(ch);}return list.stream();
} 运行结果如下:

如果觉得不好理解,看这个List的例子是否可以理解:
public static void main(String[] args) {ArrayList outlist = new ArrayList();outlist.add("aaa");ArrayList inlist = new ArrayList();inlist.add("bbb");inlist.add("ccc");//使用add方法添加一个集合outlist.add(inlist);System.out.println("add方法添加inlist:"+outlist);System.out.println("------------------");outlist = new ArrayList();outlist.add("aaa");//使用addAll方法添加一个集合outlist.addAll(inlist);System.out.println("addAll方法添加inlist:"+outlist);
}输出如下:

add方法(好比map方法)将整个inlist作为一个元素放入outlist中,因此存在中括号;
addAll方法(好比flatMap方法)将inlist中的元素取出放入outlist中,因此无中括号。
三,终止操作
方法 | 说明 |
allMatch(Predicate p) | 流中元素是否全部匹配规则p,全部匹配返回true,否则false |
anyMatch(Predicate p) | 流中元素是否有一个匹配规则p,有匹配返回true,无则false |
noneMatch(Predicate p) | 流中元素是否全部不匹配规则p, |
findFirst() | 取流中第一个元素 |
findAny() | 从流中任取一个元素 |
forEach(Consumer | 遍历并逐个消费元素 |