
C++设计模式之原型模式
举一个最简单的例子来说明原型模式:记得上小学的时候,老师把需要做的课外习题写到黑板上,而下面的我们都要把这些题抄写到自己的本子上,回家做好,第二天交上来,也就是每道题,全班50个人,每个人都要抄写一遍。按照现在的时间理论来说,就是浪费了50个人的时间。但是,那个时候条件限制,老师也是不得已而为之。现在好了,老师做一份电子版的习题,打印一份,然后拿着这份打印的原版,就可以复制出50份。
结合原型模式的概念进行分析,老师打印出来的那一份,就是“原型”,而复制出来的那50份,就是使用的“拷贝”。而原型模式就是这么简单的一个道理,通过现有的东西,再复制出一个来。
用UML类图表示原型模式
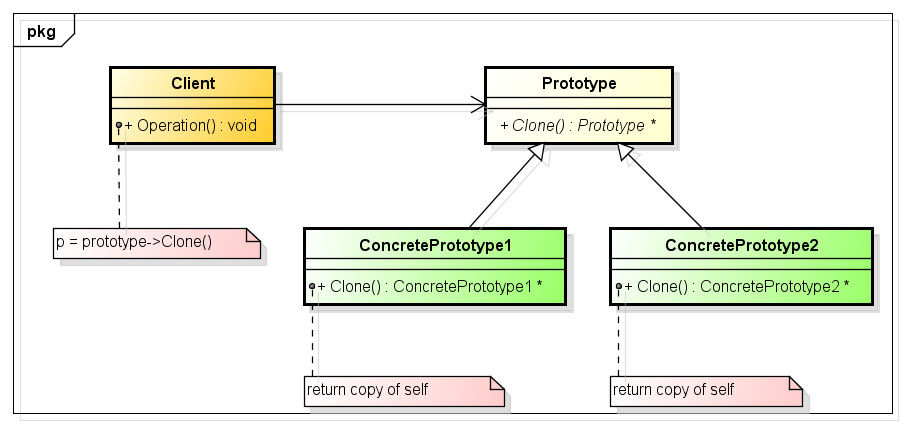
由于克隆需要一个原型,而上面的类图中Prototype就这个原型,Prototype定义了克隆自身的Clone接口,由派生类进行实现,而实现原型模式的重点就在于这个Clone接口的实现。ConcretePrototype1类和ConcretePrototype2类继承自Prototype类,并实现Clone接口,实现克隆自身的操作;同时,在ConcretePrototype1类和ConcretePrototype2类中需要重写默认的拷贝构造函数,供Clone函数调用,Clone就是通过在内部调用重写的拷贝构造函数实现的。要注意,如果要克隆的对象涉及资源的申请,那么拷贝构造函数就需要实现为深拷贝,如果不涉及资源的申请,那么拷贝构造函数实现为浅拷贝就行了。
在后续的编码过程中,如果某个类需要实现Clone功能,就只需要继承Prototype类,然后重写自己的默认拷贝构造函数就好了。
#include
using namespace std;//接口
class Prototype
{
public :Prototype(){}virtual ~Prototype(){}virtual Prototype * Clone() = 0;
};//实现
class ConcretePrototype : public Prototype
{
public :ConcretePrototype():m_counter(0){}virtual ~ConcretePrototype(){}//拷贝构造函数ConcretePrototype( const ConcretePrototype & rhs){m_counter = rhs .m_counter;}//复制自身virtual ConcretePrototype * Clone(){//调用拷贝构造函数return new ConcretePrototype (*this );}private :int m_counter;
};int main(int argc , char **argv)
{//生成对象ConcretePrototype * conProA = new ConcretePrototype ();//复制自身ConcretePrototype * conProB = conProA->Clone();delete conProA;conProA= NULL ;delete conProB;conProB= NULL ;return 0;
}
原型模式的使用场景:
原型模式和建造者模式、工厂方法模式一样,都属于创建型模式的一种。简单的来说,我们使用原型模式,就是为了创建对象。但是,在以下场景下,使用原型模式是最好的选择:
- 当我们的对象类型不是开始就能确定的,而这个类型是在运行期确定的话,那么我们通过这个类型的对象克隆出一个新的对象比较容易一些;
- 有的时候,我们需要一个对象在某个状态下的副本,此时,我们使用原型模式是最好的选择;例如:一个对象,经过一段处理之后,其内部的状态发生了变化;这个时候,我们需要一个这个状态的副本,如果直接new一个新的对象的话,但是它的状态是不对的,此时,可以使用原型模式,将原来的对象拷贝一个出来,这个对象就和之前的对象是完全一致的了;
- 当我们处理一些比较简单的对象时,并且对象之间的区别很小,可能就几个属性不同而已,那么就可以使用原型模式来完成,省去了创建对象时的麻烦了;
- 有的时候,创建对象时,构造函数的参数很多,而自己又不完全的知道每个参数的意义,就可以使用原型模式来创建一个新的对象,不必去理会创建的过程,让创建过程见鬼去吧。
所以,在上述的的情况下,在设计的时候,适当的考虑一下原型模式,减少对应的工作量,减少程序的复杂度,提高效率。
与其它创建型模式的比较:
工厂方法模式、抽象工厂模式、建造者模式和原型模式都是创建型模式。工厂方法模式适用于生产较复杂,一个工厂生产单一的一种产品的时候;抽象工厂模式适用于一个工厂生产多个相互依赖的产品;建造者模式着重于复杂对象的一步一步创建,组装产品的过程,并在创建的过程中,可以控制每一个简单对象的创建;原型模式则更强调的是从自身复制自己,创建要给和自己一模一样的对象。
总结:
原型模式作为创建型模式中最特殊的一个模式,具体的创建过程,是由对象本身提供,这样我们在很多的场景下可以很方便的快速的构建新的对象。但是,原型模式的最大缺点是继承原型的子类都要实现Clone操作,这个是很困难的。例如,当所考虑的类已经存在时就难以新增Clone操作。当内部包括一些不支持拷贝或者有循环引用的对象时,实现克隆可能也会很困难。说以说,每一种设计模式都有它的优点和缺点,在设计的时候,我们需要进行权衡各方面的因素,扬长避短。
参考文章:https://www.cnblogs.com/ring1992/p/9592911.html