
Alexa, Stop Spying on Me!“: Speech Privacy Protection Against Voice Assistants
文章目录
- Alexa, Stop Spying on Me!": Speech Privacy Protection Against Voice Assistants
- 摘要
- 两个挑战
- 主要贡献
- 威胁分析
- 威胁模型
- 保护目标
- 评估指标
- 自动干扰控制算法
- 选择性干扰
- 干扰控制管道
- 最小化唤醒词误检测
- 最大化私人语音静音速率
- 什么时候恢复干扰
- 实用的干扰设计
- 无声干扰
- 干扰单个麦克风
- 干扰麦克风阵列
- 实现
- 硬件实现
- 软件实现
Alexa, Stop Spying on Me!": Speech Privacy Protection Against Voice Assistants
Sun K , Chen C , Zhang X . “Alexa, stop spying on me!”: speech privacy protection against voice assistants[C]// SenSys '20: The 18th ACM Conference on Embedded Networked Sensor Systems. ACM, 2020.
摘要
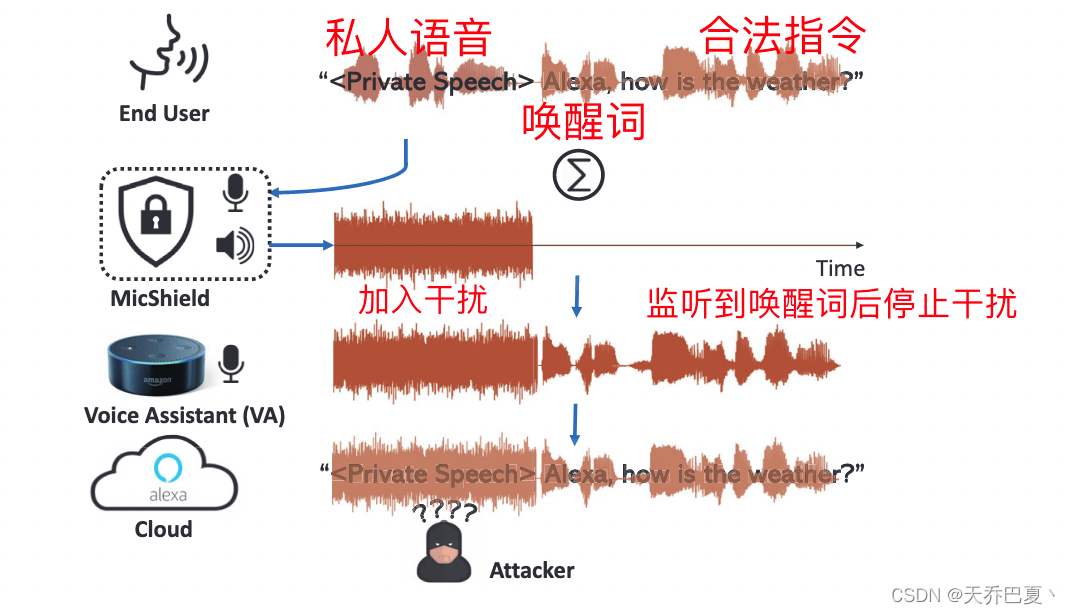
本文提出了MicShield, 这是第一个作为配套设备在VA语音助手上实施隐私保护的系统。
MicShield引入新型干扰机制,具体是指使用音素级的干扰控制管道,将合法语音命令传递给VA的同时,混淆用户的私人语音。
这种做法,可以有效保护用户隐私,同时不会影响VA的响应能力。
两个挑战
为了在不干扰语音助理日常使用的情况下保护用户隐私,需要应对两个挑战:
- 连续的干扰不仅会影响私人语音,而且还会抑制唤醒词,导致VA对后续的合法指令没有响应。【解决方案】利用了唤醒词遵循固定音素模式这一事实,即使前几毫秒被卡住,唤醒词仍然可以通过自动语音识别 (ASR) 算法识别。
- 需要克服基于麦克风阵列的潜在反制措施,这些反制措施存在于大多数现成 (OTS) VA 中。麦克风阵列可以通过声学波束成形来增强用户的声音,从而削弱 MicShield 干扰的有效性。 【解决方案】MicShield 通过增益抑制方法,该方法使麦克风饱和并完全混淆私人语音(使除唤醒词之外的声音淹没在噪声之中)。我们的设计采用声波导waveguides将干扰信号重定向到每个麦克风。同时,这些波导避免了自我干扰的问题,确保 MicShield 本身仍然可以识别干扰信号中的唤醒词。
主要贡献
-
我们引入了一种新的概念,通过有选择地干扰非预期的私人语音并传递预期的语音命令,自动保护语音隐私免受始终开启的麦克风的影响。
-
我们提出了一种新的语音处理流程,利用逐帧可能性来检测唤醒词的开始,从而实现有选择的干扰。
-
我们提出了一种用单个扬声器干扰整个麦克风阵列的方法,同时避免自我干扰。
-
我们通过低成本的OTS组件制作了纯离线的MicShield原型,并验证了它在保护语音隐私方面的有效性,而不影响语音助手的功能。
威胁分析
威胁模型
MicShield针对的场景是对手使用VA的始终在线麦克风窃听私人语音。
保护目标
MicShield 旨在在不破坏 VA 功能的前提下,防止私密语音到达 VA。
MicShield作为附加设备来执行语音隐私保护,而不修改现有VA的硬件/软件。
- 安全脱机,确保MicShield制造商不会对其造成威胁。
- 应确保唤醒词能触发VA,且唤醒词之前的隐私语音不会被识别。
- 需要解决(敌方使用麦克风阵列增强用户语音,削弱干扰)的问题。
考虑最坏的情况:
- VA接收的A加权声压级(A-weighting SPL)足够高,但是小于日常交谈的最大SPL。
- 攻击者知道语音源的确切位置,可以通过阵列波束形成来最大化语音增强。
评估指标
与传统基于密码学的安全系统不同,MicShield的安全性保证很难提供确切的安全保证。本文借鉴了Wyner无线安全系统的窃听者模型的思想,根据MicShield的功能目标定义了保护隐私级别、隐私泄漏率和破坏概率等指标来评估其性能。
- 静音率:指干扰持续时间与整个语音持续时间之比。我们的目标理论上是希望唤醒词静音率为0%,私人语音精音率为100%。
- 唤醒词误检率:唤醒词无法被正确识别的概率。设计目标是VA在有无MicShield干扰的情况下唤醒词误检率近似。
- 干扰效果:使用PESQ(语音质量评估的感知评分)和语音识别率来量化干扰效果。
自动干扰控制算法
选择性干扰
一种直观的做法,采用唤醒词检测器,检测器不断干扰,只有在听到用户定义的预唤醒词时才会停止。然而,我们的实验表明,即使是像“Alexa”这样的短唤醒词也至少需要额外 500 毫秒。因此,听不见的“Alexa”将不可避免地与紧跟在预唤醒词之后的用户语音查询重叠——这种冲突会导致 VA 发生故障。
与词级检测相比,我们建议使用音素级特征来识别早期出现的唤醒词。
当唤醒词的初始部分被干扰破坏时,能否激活 VA?
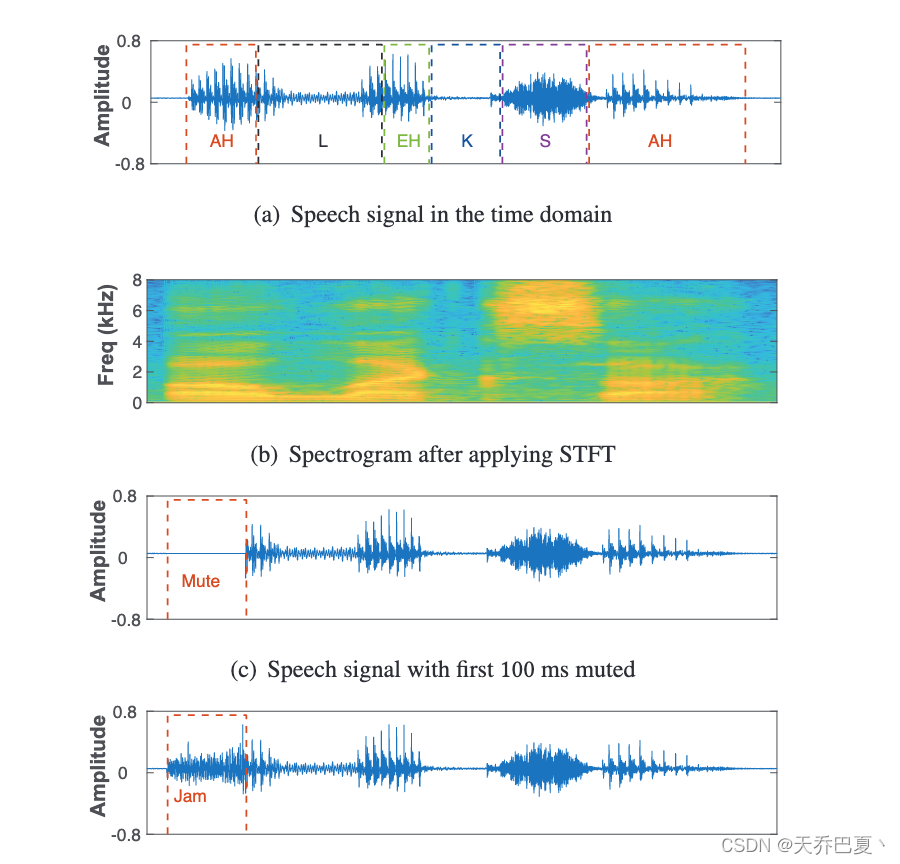
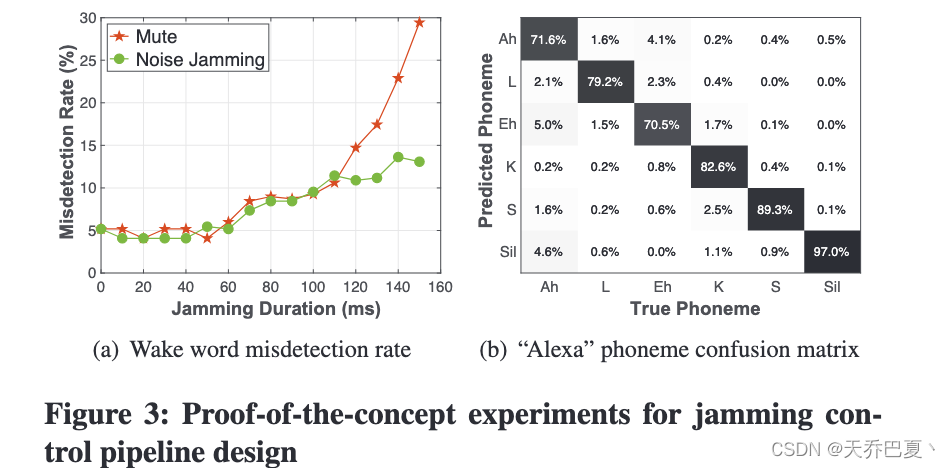
图 3(a) 显示了静音和干扰情况下唤醒词误检率与预定义初始持续时间的关系。即使前 60 毫秒静音或干扰,唤醒词仍然可以以 95% 的准确率激活,如果 MicShield 在前 60 毫秒内停止干扰,Echo Dot 仍然能够识别唤醒词和后续语音命令。这对于其他常见的唤醒词和 VA 也是如此。
干扰控制管道
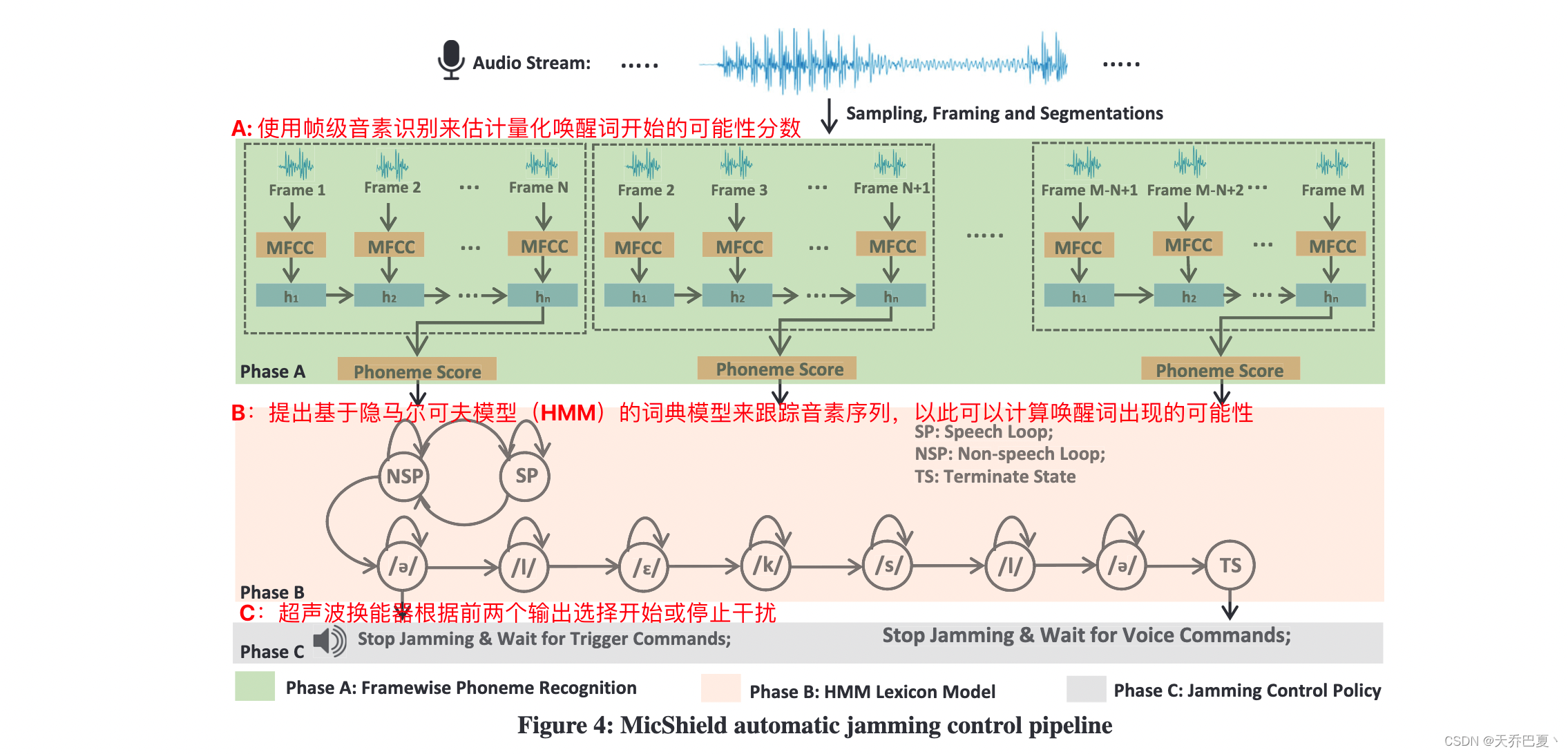
最小化唤醒词误检测
为了避免干扰 VA 的基本功能,干扰控制管道必须最大限度地减少唤醒词误检率。需要面对两个挑战:
- 音素级挑战,相比于词级识别,帧级音素级识别方法的准确性较低。通过将音素识别模型训练为对与唤醒词相关的特定音素敏感,最终准确率达到78.7%。
- 词典级挑战,通过降低 B 阶段的 HMM 似然阈值进一步降低唤醒词误检率。但是这样会导致私人语音静音率过低,降低抗干扰效果,因此需要考虑两者之间的平衡。还有就是,这会增加误报率,但这并不会影响最终结果,因为误报的语音信号会传递给VA重新处理。只要唤醒词没有被识别,VA就不会被激活。
最大化私人语音静音速率
确保用户私密语音尽可能被干扰信号成功地混淆。
在实际应用中,框架音素识别模型并不完美。为了降低唤醒词的误检率,我们的微调模型对唤醒词中出现的音素很敏感(第4.3节),这反过来又增加了音素虚警率,定义为唤醒词音素被错误识别时的概率。这反过来又会降低私人语音静音率。
比如MicShield可能会混淆Alexa和Apple的第一个音素,并决定不堵塞“Apple”的第一个音素。
为了解决这个问题,我们使用HMM词典模型来跟踪基于预期唤醒词的音素序列模式。通过这种方法,一旦发现意外的音素序列,MicShield将立即重新开始干扰。因此,即使在音素级虚警率相对较高的情况下,唤醒词识别仍然可以保持较低的虚警率。
什么时候恢复干扰
一旦 VA 回到非活动模式,MicShield 就需要恢复干扰。 VA 返回非活动模式主要有两种策略。
- 它在触发后检测足够长的静默期。
- 它根据语义内容识别语音命令的结束。实用的 VA 设备采用语音活动检测 (VAD) 方法和语义内容解释来实现这些策略。
MicShield 使用 VAD 方法 [48] 来实现第一个策略。例如,我们凭经验发现 Amazon Echo 和 Google Home 分别使用 7 秒和 8 秒的 VAD 阈值。
实用的干扰设计
无声干扰
为避免打扰用户,MicShield 使用听不见的声音来干扰麦克风。
具体来说,我们使用超声波换能器来传输超声波信号。
干扰单个麦克风
传统的频率失真干扰方法很容易干扰单个麦克风,通过传输白噪声和彩色噪声来降低语音信噪比。
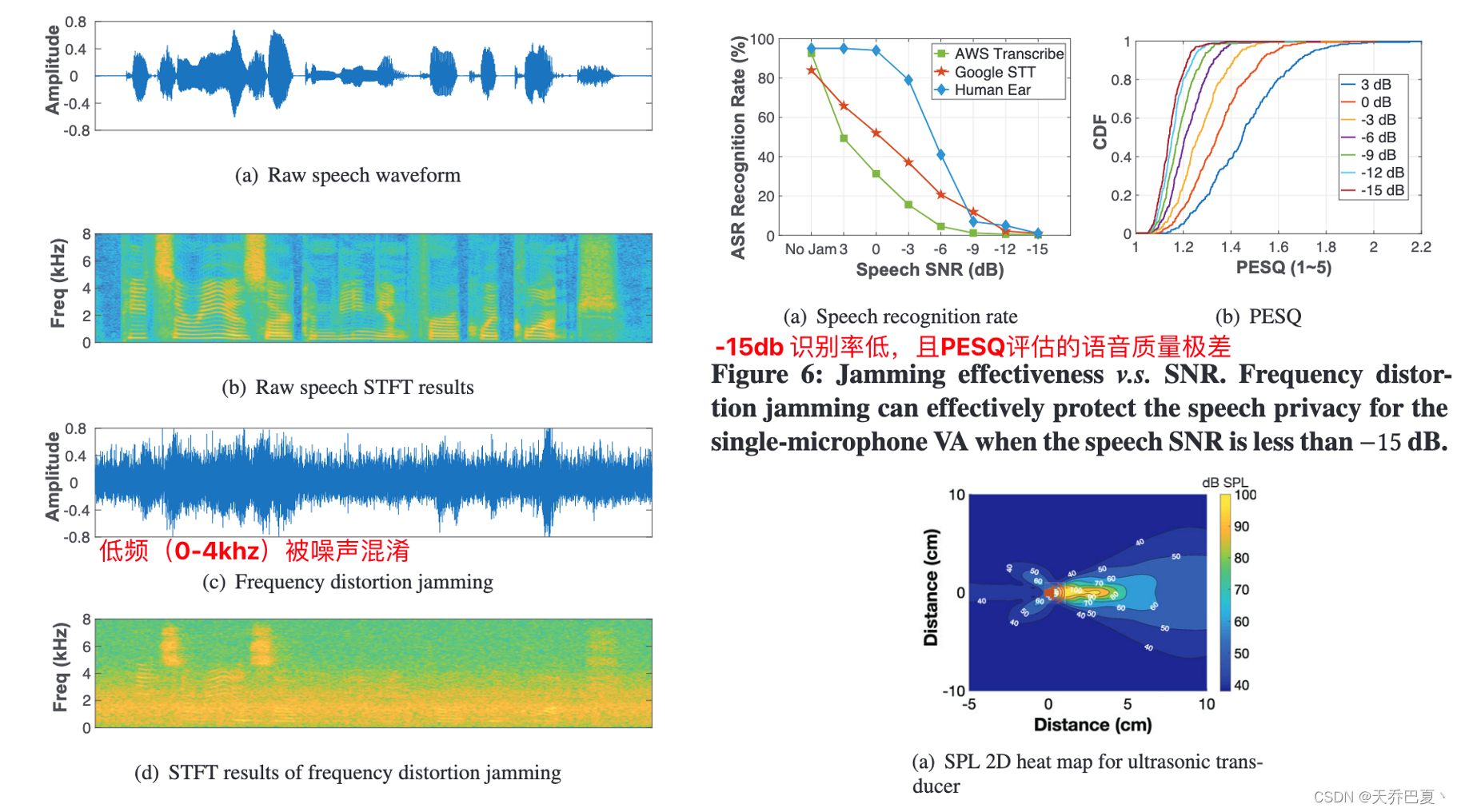
实验表明,当语音信噪比小于−15 dB 时,频率失真干扰可以有效地保护单麦克风 VA 的语音隐私。要在 75 dBA 的最高语音 SPL(第 3 节)下将 SNR 限制在 -15 dB 以下,相应的噪声 SPL 应高于 90 dBA。为了检查这种干扰噪声量的可行性,我们测量了单个换能器在其最大音量下产生的 SPL。
我们看到频率失真干扰达到所需的 90 dBA SPL,只有当 MicShield 的超声波换能器被放置在距离麦克风 4 厘米以内时。
干扰麦克风阵列
一、基于波束成形的攻击
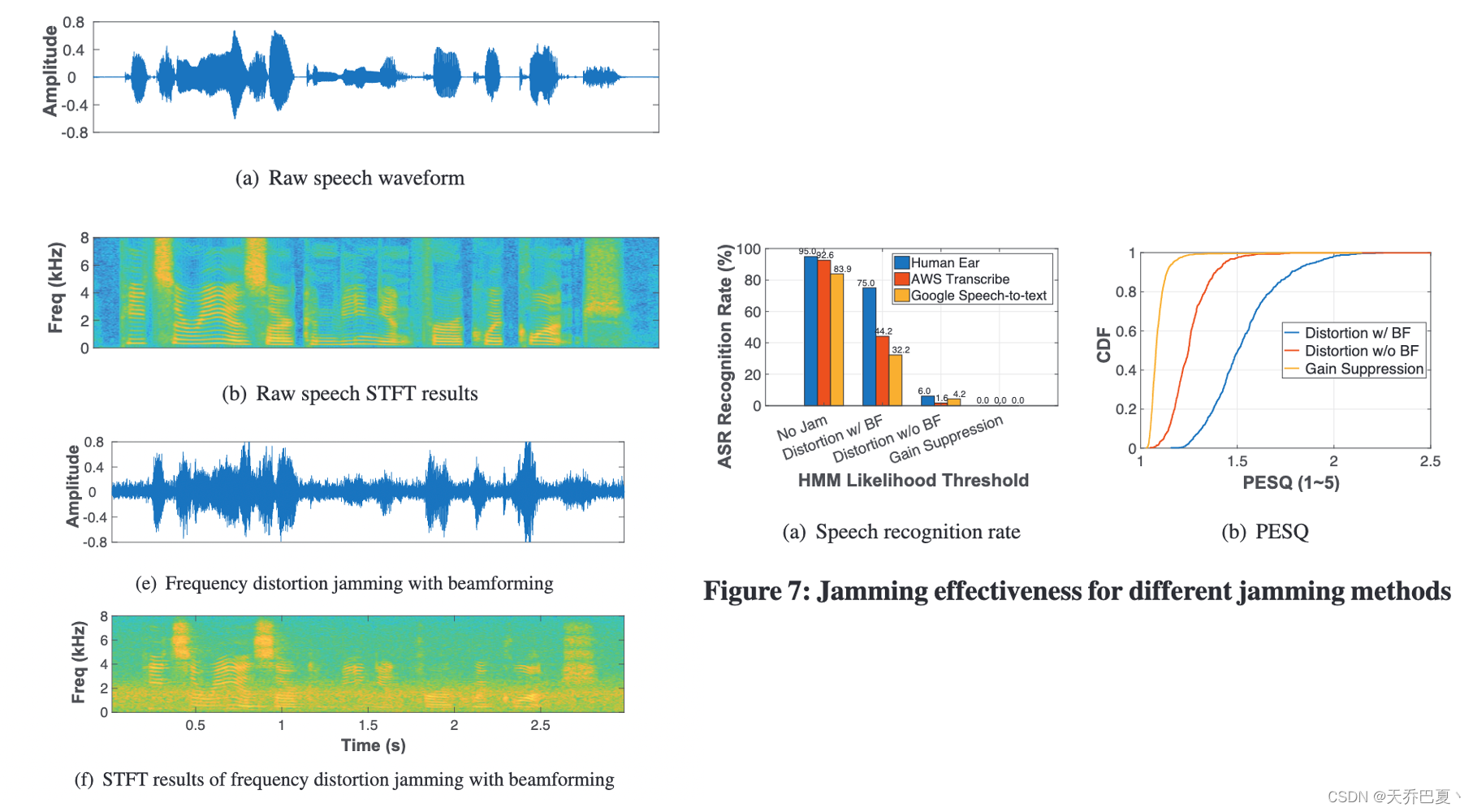
采用波束成形后,语音波形和 STFT 结果比没有波束成形的情况更接近原始音频信号。 麦克风波束成形对抗措施可以将语音信噪比提高12 dB。
二、增益抑制干扰。
为了有效地击败基于波束形成的对抗措施,我们探索了一种替代的增益抑制干扰方法。这个想法是传输高音量声音以使麦克风饱和,即迫使麦克风达到声学过载点 (AOP)。当压倒性的输入声压导致麦克风输出严重失真时,就会出现 AOP [56]。
需要解决两个难题:
- 干扰噪声音量和可听度之间的两难选择
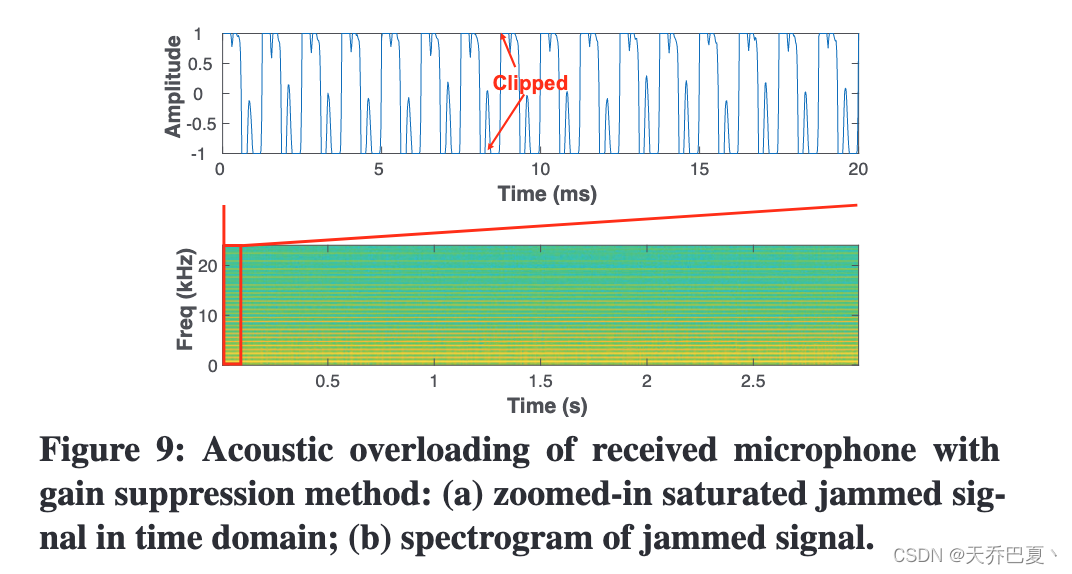
图9显示了被单频信号干扰的私人语音的波形(见图5(A))。显然,麦克风变得饱和,语音信号被削波并失真成方形波形,也失去了典型的频域特征。我们的测试表明,混淆后的信号具有较低的PESQ为1.09,使用Amazon转录[39]和Google STT[40]的语音识别率为0%。
- 干扰噪声音量和覆盖范围之间的两难境地
测量结果表明,当声压级超过100-110分贝时,会发生完全增益抑制。这意味着当声音强度达到该水平时,设备的麦克风无法正常放大声音信号。在图8(b)中,黄色区域表示在使用3W放大器的情况下,声音源距离麦克风小于14厘米时会发生增益抑制。然而,对于多麦克风的语音助手来说,单个干扰源无法覆盖整个麦克风阵列。即使使用放大器,当干扰源距离麦克风阵列一定距离时,增益抑制的最大半径也只有4.5厘米,无法覆盖一些主流智能音箱(如Google Home和Apple HomePod)的半径范围。
三、声导设计
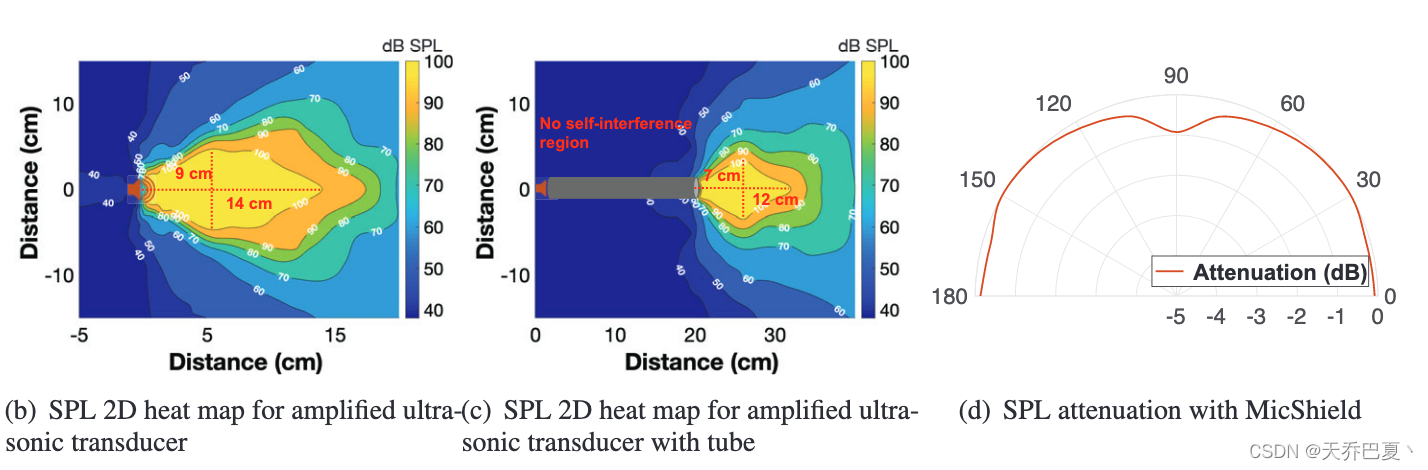
为了解决D2的困境,我们设计了一种物理屏蔽,它可以扩大单个超声换能器的覆盖范围,以干扰大型麦克风阵列。我们的基本想法是利用声波导重定向干扰信号,使多个麦克风完全饱和。
波导由长度为 20 厘米并连接到单个超声波换能器的柔性硅胶管产生。它表明,声音比没有电子管的情况更具方向性。因此,声波导也隔离了 MicShield 超声波换能器对其自身麦克风的自干扰。因此它可以在干扰 VA 的麦克风时继续检测唤醒词。同时,它提高了方向性,从而提高了声音信号的传播距离(见图 8(c))。因此,如果我们可以将换能器与多个声管连接起来,每个声管都可以阻塞阵列中的一个麦克风。
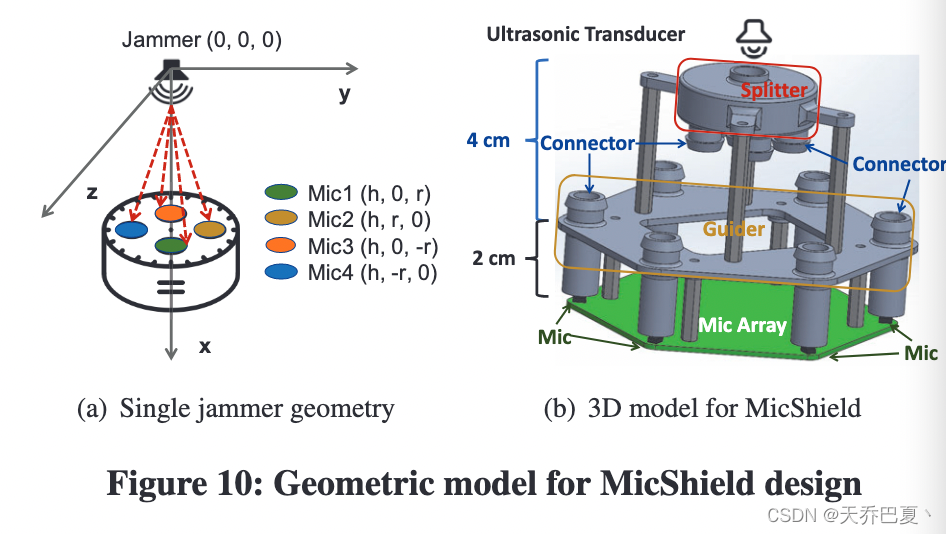
我们设计了一个“声学多路复用器”来将声学干扰信号拆分到多个管中。图 10(b) 显示了 3D 模型设计,它包含两个部分,即“分离器”(顶部)和“导向器”(底部)。超声波换能器从“分离器”顶部发射干扰信号。 “分离器”的底部包括多个连接器,这些连接器通过管子连接到“导向器”。然后,“引导器”使用另一组管子将干扰声引导到 VA 的每个麦克风,从而实现增益抑制干扰。
MicShield 的另一个实际问题是超声安全问题。正如世界卫生组织 (WHO) 所建议的那样,当暴露持续时间每天不超过 4 小时时,40 kHz 空气传播声辐射的人体暴露限值应低于 110 dB SPL [61]。如图 8(d) 所示,MicShield 保证传输的 SPL 始终在安全范围内。此外,我们的声波导设计进一步隔离了超声波并缩小了高声压级区域,以防止对用户造成伤害。
实现
硬件实现
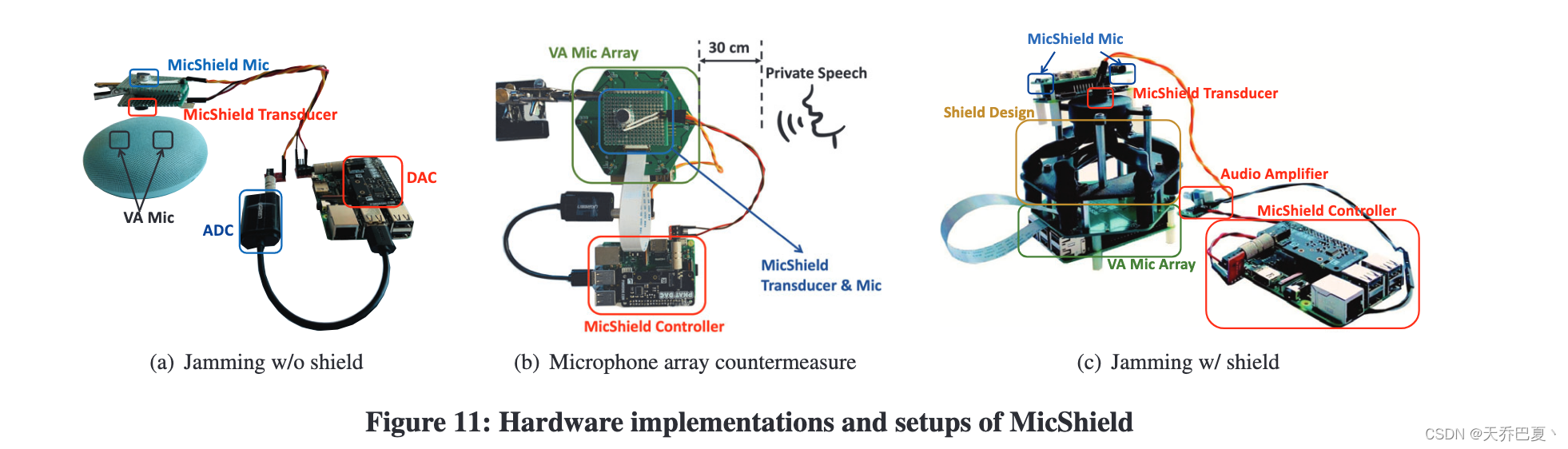
11a:用于单麦克风情况
11b:用于麦克风阵列
11c:将干扰声音引导至多个麦克风
DAC是数字模拟转换器(Digital-to-Analog Converter)的缩写。它是一种电子器件,将数字信号转换为模拟信号
ADC是模拟数字转换器(Analog-to-Digital Converter)的缩写。它是一种电子器件,将模拟信号转换为数字信号
软件实现
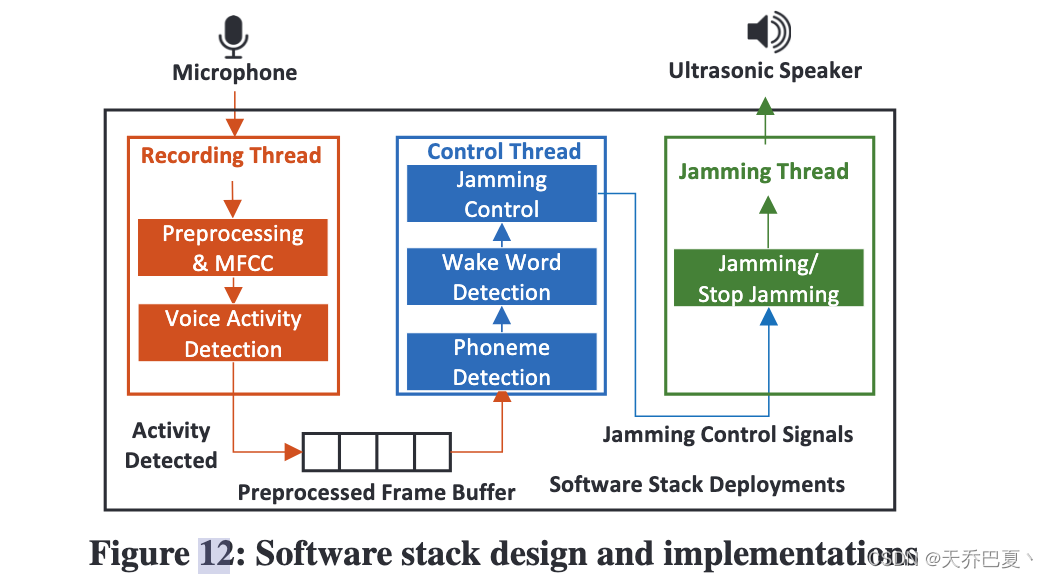
三个并行线程:记录、控制、干扰。
记录线程:根据A阶段的策略捕获和预处理声音信号,并且利用VAD检测是否需要发出干扰信号。
控制线程:将每个MFCC帧特征连同先前预处理帧的MFCC特征作为输入,根据自动干扰控制算法的结果决定是否将干扰命令传递给干扰线程。
干扰线程:收到堵塞控制后,干扰线程将开始堵塞。